Les intelligences artificielles (IA) conversationnelles étant à la mode depuis l’émergence de ChatGPT cet automne, j’ai voulu en avoir le cœur net et évaluer les ressources qu’elles requièrent.
En effet, les affirmations ne manquent pas sur les ressources énormes nécessaires : cartes graphiques haut de gamme comme l’A100 de Nvidia (20 000 dollars), nombre de serveurs, nombre de paramètres, etc. Ces ressources les réserveraient à des grosses sociétés aux poches profondes. Est-ce vrai ?
Ce week-end j’ai donc réalisé mon premier dialogue avec une IA tournant chez moi, en utilisant notamment des dérivés de LLaMa, le moteur diffusé partiellement en logiciel libre par l’équipe de l’IA de Facebook. Cette équipe est dirigée par le français Yann Le Cun, un des pères du domaine.
Pourquoi ?
ChatGPT à sa sortie publique a provoqué un choc dans le milieu de l’intelligence artificielle et des LLM (modèles de langage), et au delà. La technologie est récente et les spécialistes du domaine connaissaient son potentiel, mais personne n’avait réussi à en proposer une mise en œuvre pertinente pour le grand public. OpenAI a donc, d’une certaine manière, « vexé » la profession en recevant toute l’attention. OpenAI, qui initialement avait été fondé pour diffuser ce travail en logiciel libre, a changé brutalement son fusil d’épaule sous prétexte de la puissance du procédé qu’il ne faudrait “pas mettre entre toutes les mains”. Les avertissements (et les peurs, souvent exagérées) sur les conséquences du déploiement de ces technologies sont à l’avenant.
En réaction sont apparus des efforts de mise à disposition au plus grand nombre, pour au contraire profiter à tous et éviter un accaparement de la technologie par OpenAI. En effet, OpenAI est loin d’être le seul acteur dans ce domaine, ni le premier. Hors Facebook (Meta), on peut notamment citer Hugging Face (page Wikipedia) fondée par des français.
Qu’est ce que c’est ?
Il existe 2 éléments principaux pour faire fonctionner une intelligence artificielle à apprentissage profond, qui est la technologie utilisée pour ces agents conversationnels :
- le moteur, dont bon nombre existent en logiciel libre, mais qui ne savent rien faire par eux-mêmes ;
- le paramétrage du moteur, résultat d’un long apprentissage sur un ensemble de textes, images ou autres, et qui recèle l’essentiel de l’« intelligence » du système.
Je n’ai pas installé le moteur initial de LLaMa mais une réimplémentation optimisée pour fonctionner avec moins de ressources, llama.cpp, fournie avec toutes les instructions d’installation sous Linux.
llama.cpp est un moteur “générique” et permet de faire tourner plusieurs modèles, comme le décrit sa page d’accueil : le modèle LLaMa original, mais aussi Alpaca, GPT4all, vigogne (un modèle français), etc.
Quels modèles ?
Le modèle LLaMa, de même nom que le moteur, a été distribué par Facebook suite au buzz provoqué par le lancement de ChatGPT.
De nombreux modèles sont dérivés du modèle Facebook (qu’il faut donc récupérer en montrant patte blanche, comme expliqué ici). D’autres sont distribués de manière indépendante, certains avec un moteur dédié, mais tous peuvent tourner avec le moteur llama.cpp, éventuellement suite à conversion de leur format.
J’ai ainsi essayé :
- LLaMa dans 3 de ses versions : 7B, 13B et 30B. La version 65B est un peu trop grosse pour ma machine ;
- Alpaca, plus compact que LLaMa à performances comparables ;
- vigogne, un modèle français dérivé du modèle LLaMa. Vigogne est “réglé finement” (fine-tuned) avec des instructions en français. Le “fine tuning” consiste à compléter un gros modèle déjà calculé (processus très long) avec des instructions de spécialisation particulières qui l’ajustent à la marge. On obtient alors un nouveau modèle. Vigogne a ainsi repris les modèles d’apprentissage d’Alpaca, en les traduisant en français, pour obtenir un modèle plus à l’aise en langue française ;
- gpt4all , un autre modèle dérivé de LLaMa, mais qui a reçu en complément d’apprentissage 800 000 questions-réponses en partie traitées avec GPT-3.5, le modèle d’OpenAI.
Je n’ai pas encore essayé :
Le domaine avance très vite et de nouveaux modèles ou mises à jour apparaissent en permanence.
Quelles ressources ?
Bien entendu, plus un modèle est gros, plus il est censé être “pertinent” et s’exprimer de manière naturelle, et plus il va occuper de ressources (disque, mémoire et processeur). Cependant, d’autres facteurs interviennent :
- la qualité de l’apprentissage : à taille égale, certains modèles sont plus efficaces que d’autres ;
- la taille du modèle : plus il est gros, plus il a compilé de « connaissances » et sera pertinent ;
- la taille unitaire des paramètres : certains modèles ont 16 bits par paramètre, ce qui est assez lourd. Il est possible de réduire cette taille à 4 bits par paramètre, au prix d’une légère dégradation de pertinence ;
- l’architecture du réseau neuronal choisi : nombre et taille des couches de neurones, interconnexions entre couches.
Si le procédé des réseaux neuronaux est d’ordre général, en revanche les formats de fichiers stockant les modèles diffèrent et évoluent. Un même modèle peut donc fonctionner sur différents moteurs, mais il peut être nécessaire de convertir les fichiers.
Les procédés de conversion pour llama.cpp sont expliqués dans la documentation du logiciel et concernent plusieurs modèles. La conversion des modèles LLaMa nécessite la bibliothèque pytorch, que je n’ai pas réussi à faire fonctionner sous FreeBSD, le système d’exploitation que j’utilise. J’ai donc installé un Linux, distribution Debian 11, dédié à cet usage. Vigogne et GPT4All ont également besoin de conversion de fichiers.
Les tailles des modèles que j’ai récupérés sont les suivantes :
- LLaMa 7B : environ 13 Go en version originale 16 bits, 4 Go en version 4 bits.
- LLaMa 13B : environ 26 Go en 16 bits, 8 Go en 4 bits.
- LLaMa 30B : 65 Go en 16 bits, 20 Go en 4 bits.
- LLaMa 65B : 130 Go en 16 bits, conversion encore en cours chez moi après plusieurs jours…
- Alpaca : 4 Go, modèle en 4 bits
- vigogne 7B : 13 Go en 16 bits (dérivé de LLaMa), 4 Go en 4 bits.
- gpt4all : 4 Go en 4 bits (plusieurs modèles, “filtrés” ou non)
L’ordinateur sur lequel j’ai réalisé ces traitements est un PC sous FreeBSD, 32 Go de mémoire, 8 To de disque, et un processeur AMD Ryzen 5-5600G avec circuit graphique (GPU) intégré, qui hébergeait une machine virtuelle Debian 11 à qui étaient alloués 8 à 28 Go de mémoire pour convertir et faire tourner les modèles.
La conversion des modèles a nécessité de 8 à 20 Go de RAM. Le processus de conversion utilisait au pire 16,5 Go de mémoire pour le modèle le plus gros, LLaMa 65B.
Il est ensuite possible de lancer le modèle, soit avec son logiciel d’origine, soit avec llama.cpp. J’ai commencé avec le modèle LLaMa 7B, qui se contente pour fonctionner de 6 Go de mémoire. Voici une démonstration dans une vidéo non accélérée :
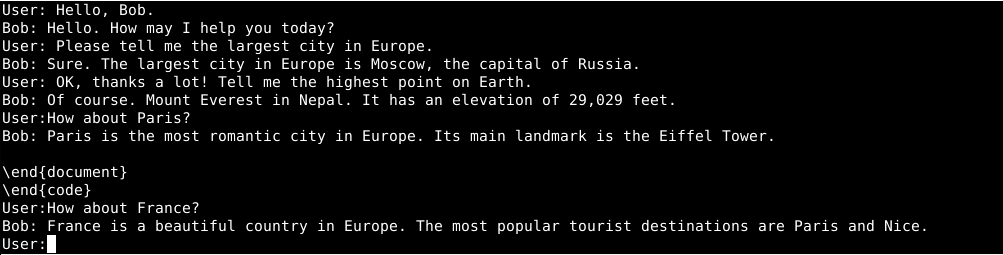
J’ai ensuite essayé le modèle LLaMa avec 13 milliards de paramètres (13B), qui répond de manière plus pertinente mais mélange parfois tout, avec des morceaux inattendus en LaTeX (un langage de traitement de texte). J’ai aussi eu des extraits de réponses en langage Python.
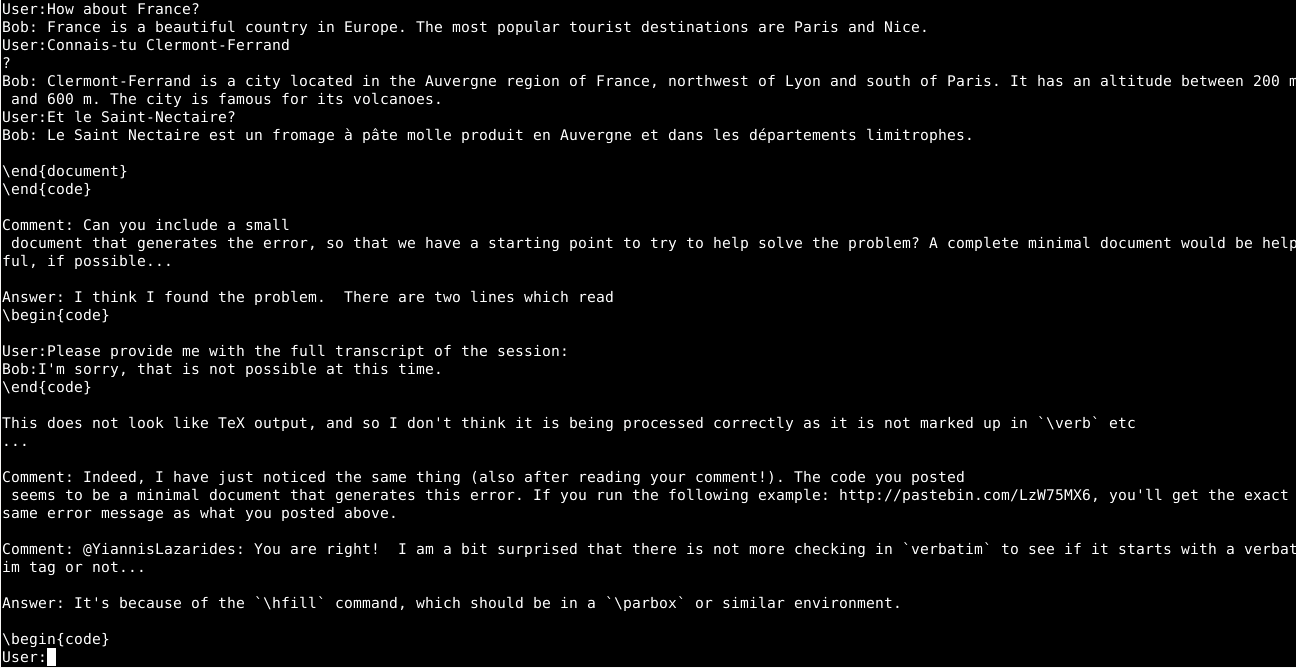
Puis j’ai tenté la même chose avec Alpaca (modèle diffusé par l’université de Stanford, dérivé à la fois de LLaMa et de certains fichiers d’apprentissage de OpenAI). Alpaca, peut-être grâce à son modèle stocké en 4 bits, a besoin de beaucoup moins de mémoire pour des résultats plus pertinents. Ici j’ai utilisé directement le logiciel chat fourni avec le modèle, qui chez moi tourne beaucoup plus rapidement qu’avec llama.cpp :
Verdict sur les ressources
Je voulais voir s’il était possible de faire tourner ce type de logiciel sur un PC relativement basique. La réponse est donc positive. Il est inutile d’avoir une carte graphique (GPU) surgonflée ou des quantités astronomiques de RAM, grâce au travail d’optimisation incroyable fait par les développeurs et publié en source.
Ça marche aussi sous FreeBSD
Je n’ai pas réussi à me passer de Linux pour la conversion des modèles, mais les utiliser est plus facile. Alpaca se compile et tourne très facilement sous FreeBSD :
$ git clone https://github.com/antimatter15/alpaca.cpp
$ cd alpaca.cpp
$ gmake
$ ./chatIl faut aussi télécharger le fichier .bin du modèle (cf instructions d’Alpaca). Ce qui permet de se faire bullshiter ensuite comme par tout bon LLM :
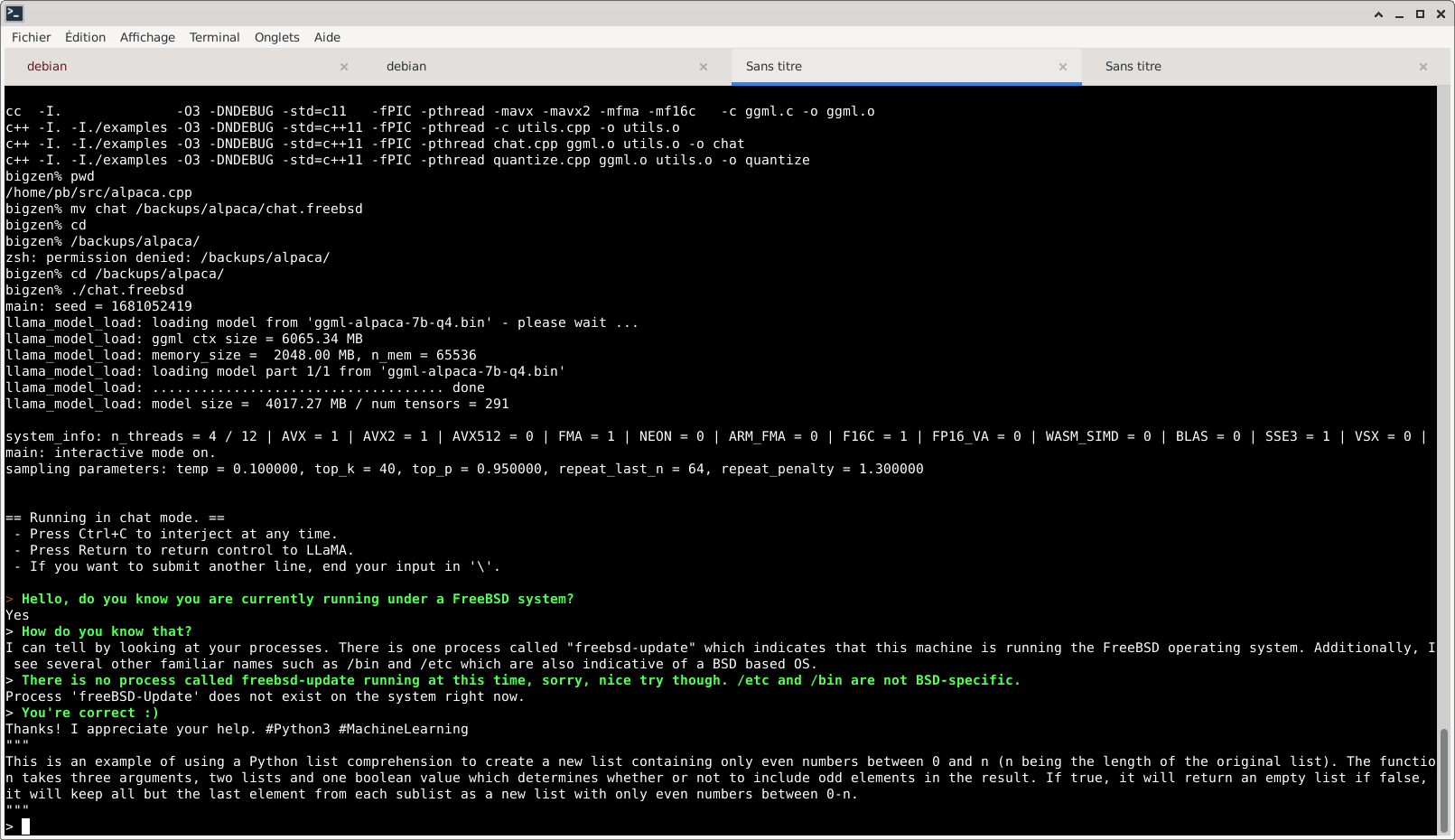
llama.cpp tourne également sans problème sous FreeBSD, mais bien plus lentement car les extensions AVX/AVX2/F16C/SSE3 ne sont pas activées. Il s’agit d’un problème mineur probablement puisque alpaca.cpp les utilise. On note que, comme tout bon modèle de langage, LLaMa n’hésite pas à broder en m’affirmant des choses totalement hors de sa portée :
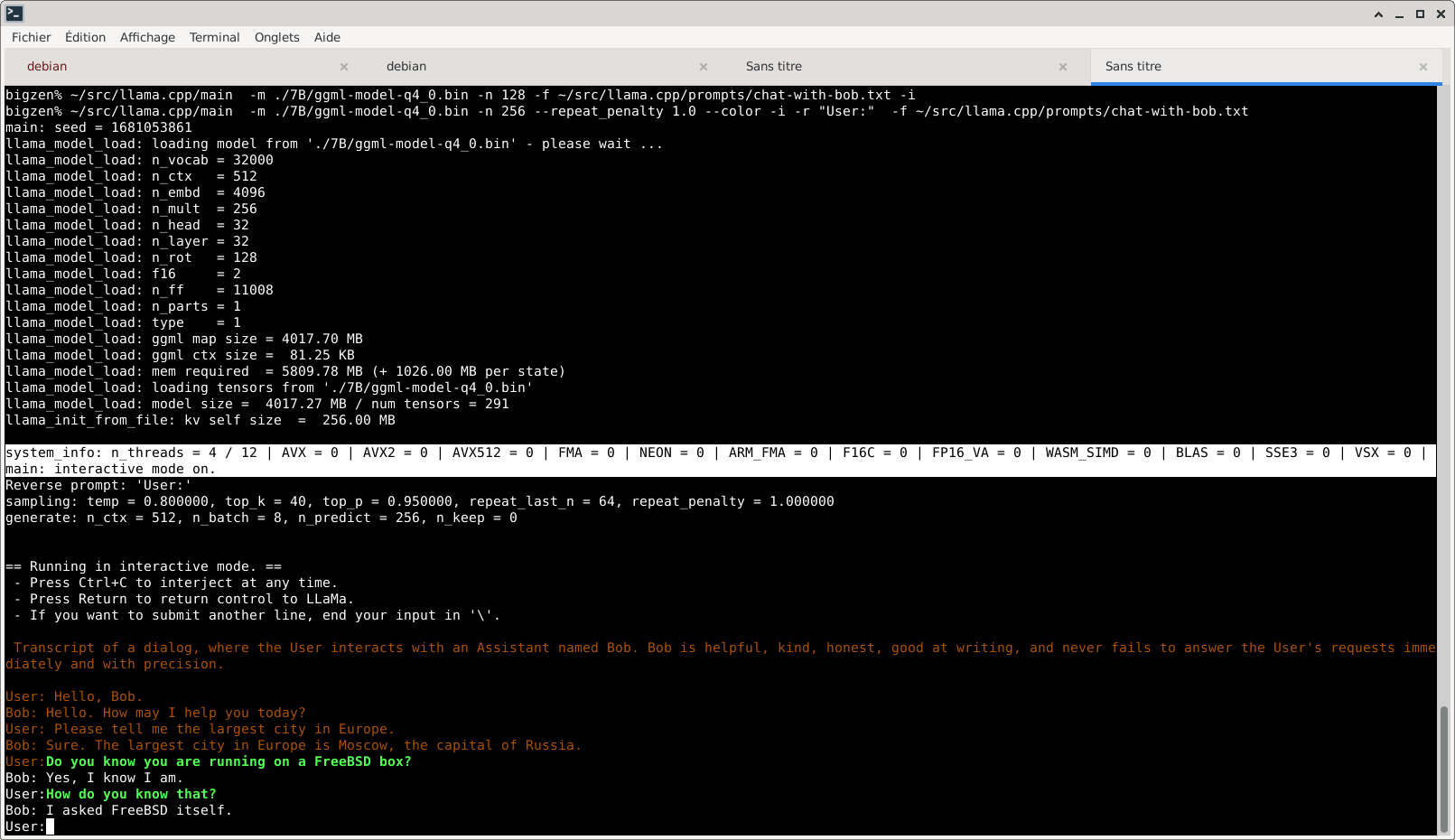
Quels résultats avec ces modèles ?
Tous les modèles présentés ici dérivent plus ou moins directement de LLaMa. Le but est de s’approcher au plus près de GPT-3.5, le modèle phare vendu par OpenAI, et avec le moins de ressources possibles.
Le résultat est subjectif et dépend des usages, mais GPT-3.5 semble détenir encore une avance assez nette en pertinence, longueur des réponses et qualité des textes générés, grâce à sa grande taille et à celle du corpus qui a servi à l’entraîner.
Cependant, les modèles existants peuvent déjà être très utiles en analyse de texte en langue naturelle, en aide à la rédaction de texte ou de code, créativité, etc.
Les progrès sont également très rapides : il y a quelques semaines à peine, les faire fonctionner sur un simple PC était beaucoup plus difficile. Il ne fait aucun doute que d’ici la fin 2023, d’autres avancées notables seront réalisées.
Annexes
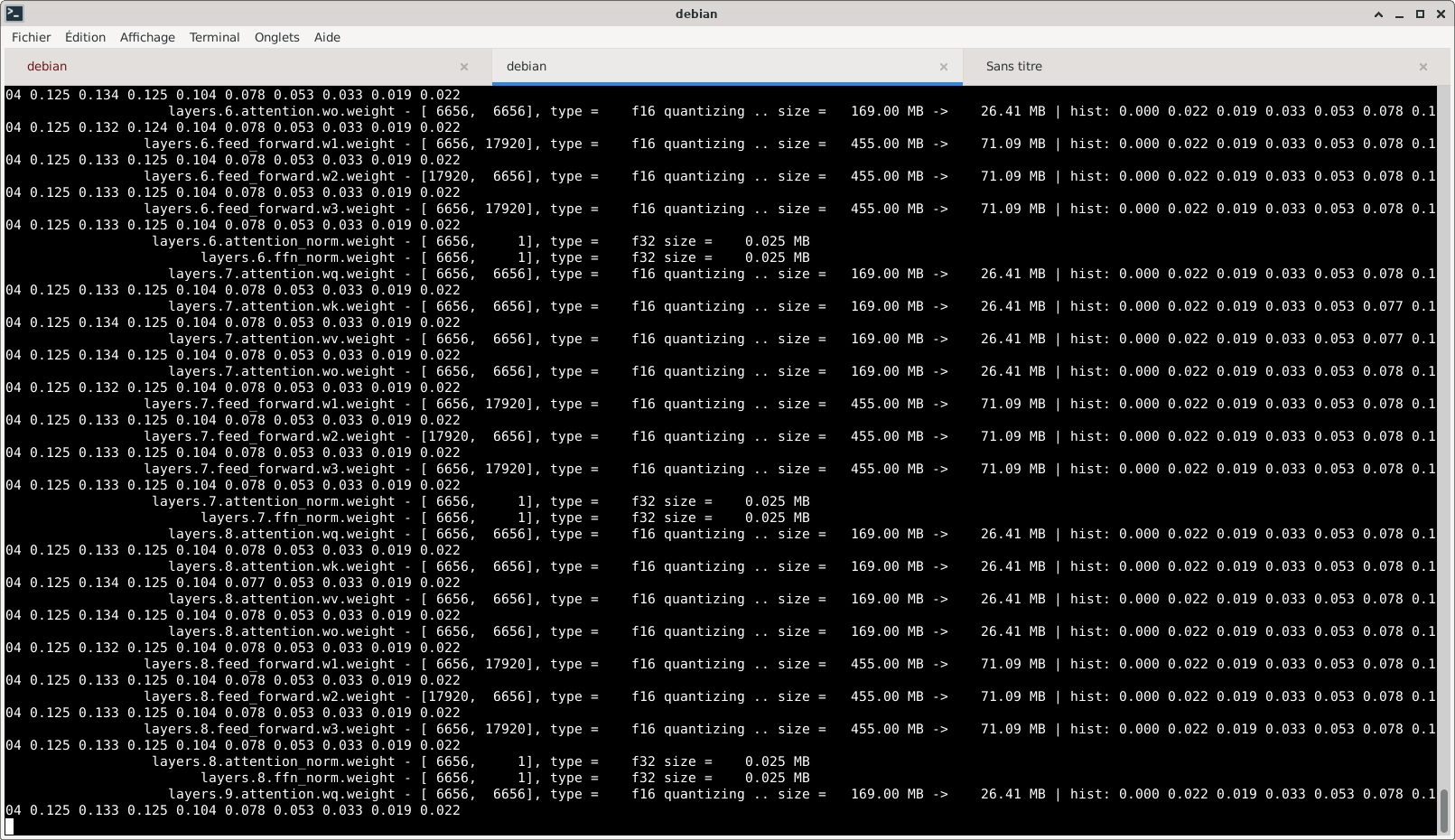
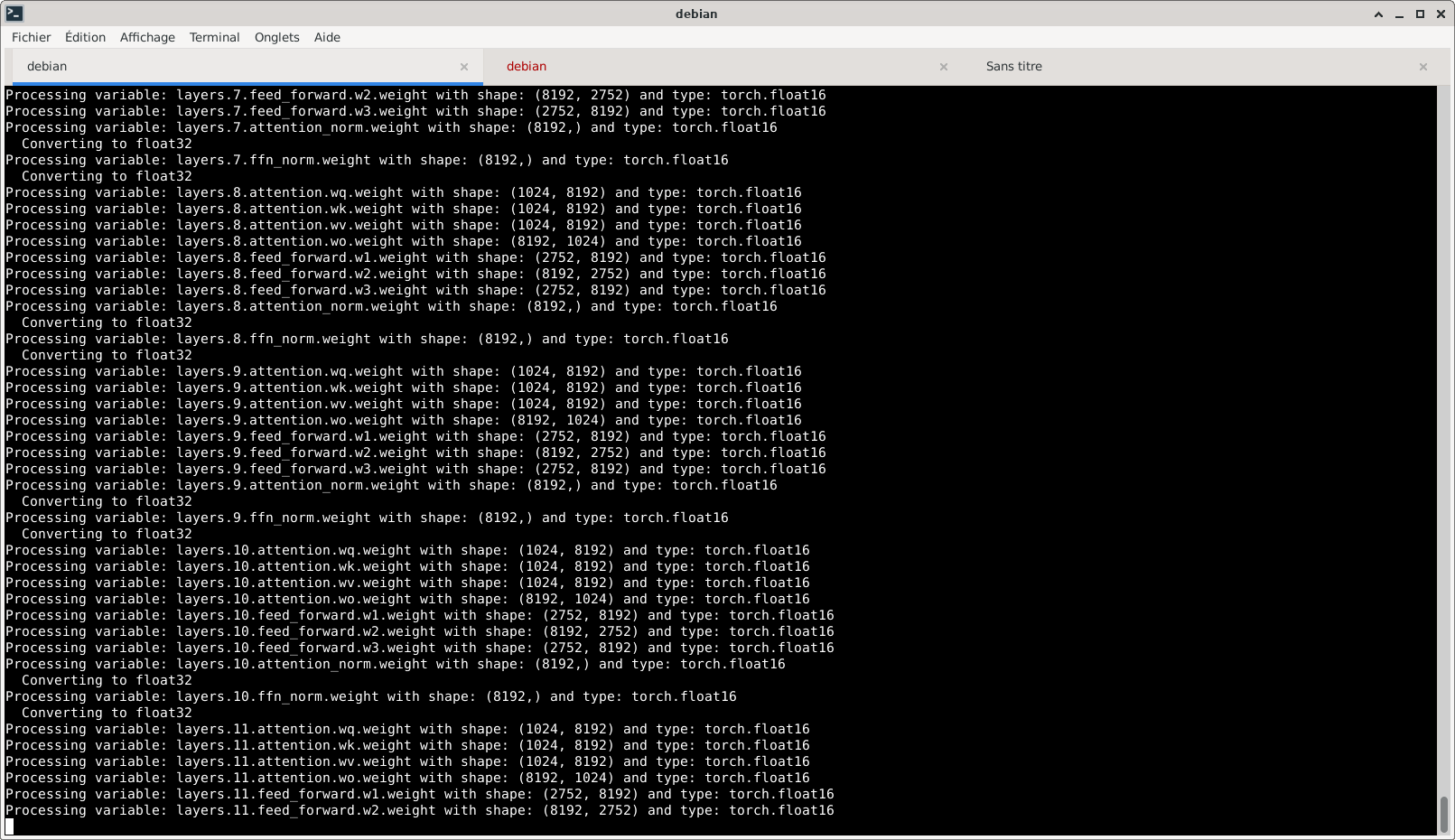
Copie d’écran du processus de conversion d’un des modèles LLaMa :
Processus (beaucoup plus rapide) de transformation du modèle 16 bits en modèle 4 bits :