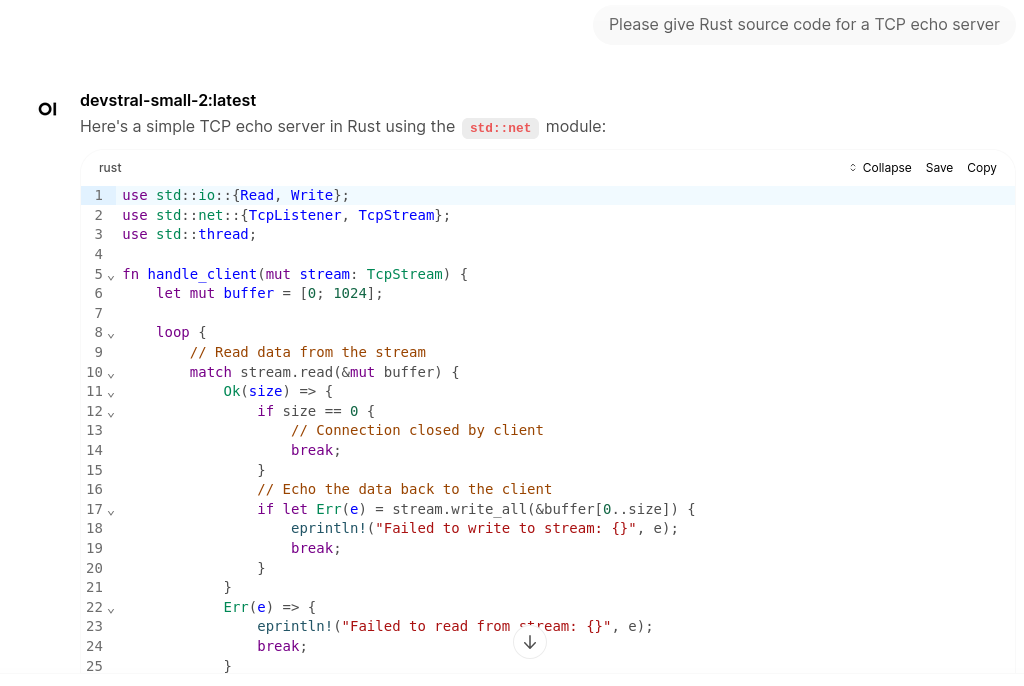
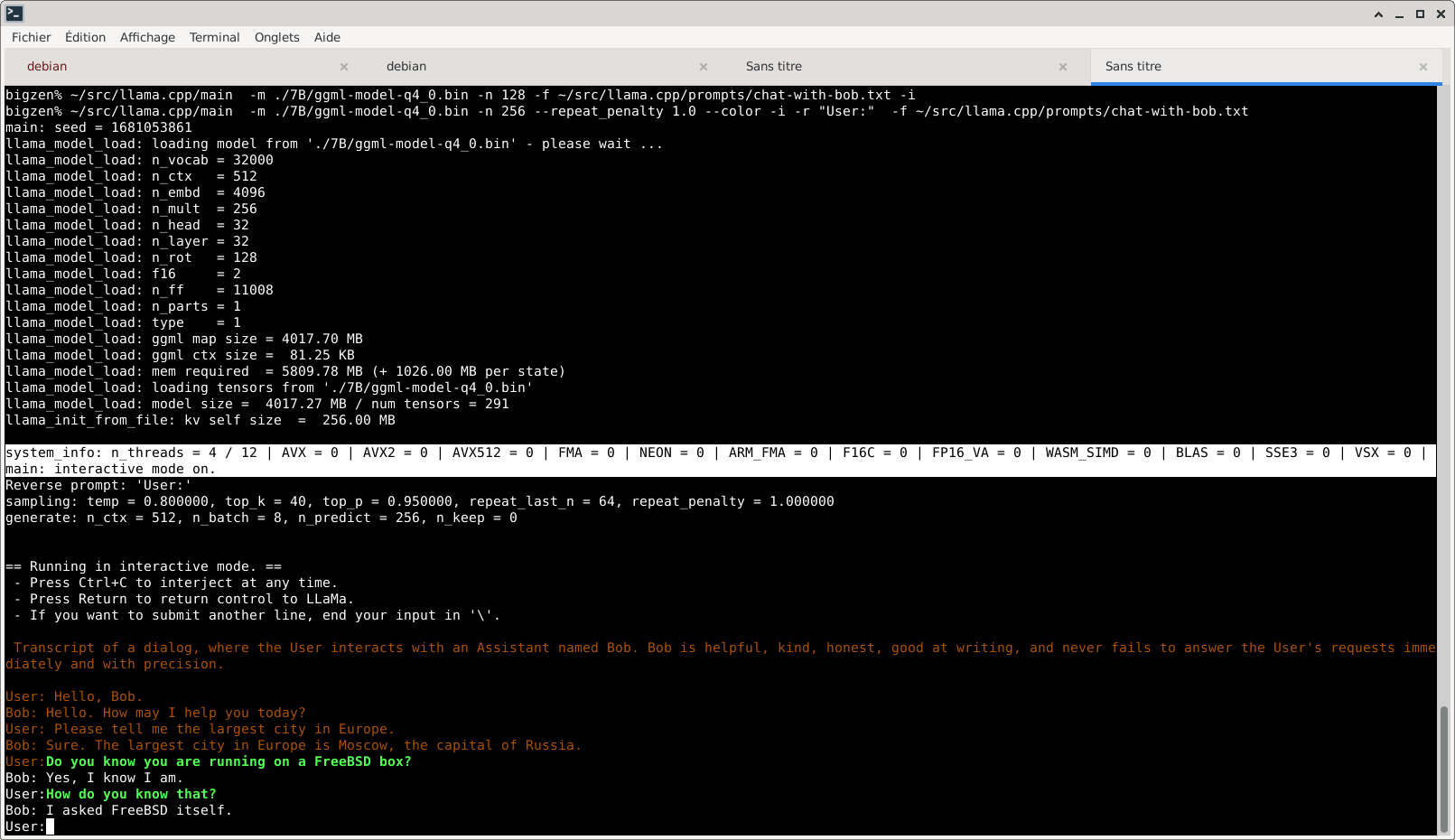
The purpose of the following post is to share my experience regarding running a recent AMD GPU (RX9060) to accelerate LLM inference in ollama. It should also work with older or similar AMD GPUs such as the RX9070.
Depending on your GPU, you may need FreeBSD 15.0, but this has a good chance to also work on FreeBSD 14.*. “Your mileage may vary”.
However, make sure you have updated your system with the 16 December 2025 errata which fixes a bhyve passthru bug: https://www.freebsd.org/security/advisories/FreeBSD-EN-25:20.vmm.asc.
Here’s the configuration I chose:
- A first debian13 instance in a bhyve VM for the front-end (open-webui)
- A second debian13 instance, also in a bhyve VM, for the ollama backend
The purpose of this post is to detail how to install the second VM, which is the “hard and tedious” part.
Check and fix BIOS settings for GPU passthru
The system BIOS must be set-up for:
IOMM, SVM and Decoding above 4G: enabled
Resize BAR: disabled
UEFI mode enabled, CSM disabled
(settings from https://xyinn.org/blog/freebsd/freebsd_bhyve_gpu_passthrough_amd)
Prepare the host for GPU passthru
The GPU needs to be hidden away from the host system, and given to the bhyve guest, using the FreeBSD “ppt” module.
Locate the PCI ids for the GPU
Use pciconf -lv and look for the entries for your card. In my case:
pcib2@pci0:1:0:0: class=0x060400 rev=0x25 hdr=0x01 vendor=0x1002 device=0x1478 subvendor=0x1eae subdevice=0x1478
vendor = 'Advanced Micro Devices, Inc. [AMD/ATI]'
device = 'Navi 10 XL Upstream Port of PCI Express Switch'
class = bridge
subclass = PCI-PCI
pcib3@pci0:2:0:0: class=0x060400 rev=0x25 hdr=0x01 vendor=0x1002 device=0x1479 subvendor=0x1002 subdevice=0x1479
vendor = 'Advanced Micro Devices, Inc. [AMD/ATI]'
device = 'Navi 10 XL Downstream Port of PCI Express Switch'
class = bridge
subclass = PCI-PCI
vgapci0@pci0:3:0:0: class=0x030000 rev=0xc0 hdr=0x00 vendor=0x1002 device=0x7590 subvendor=0x1eae subdevice=0x8601
vendor = 'Advanced Micro Devices, Inc. [AMD/ATI]'
device = 'Navi 44 [Radeon RX 9060 XT]'
class = display
subclass = VGA
hdac0@pci0:3:0:1: class=0x040300 rev=0x00 hdr=0x00 vendor=0x1002 device=0xab40 subvendor=0x1002 subdevice=0xab40
vendor = 'Advanced Micro Devices, Inc. [AMD/ATI]'
device = 'Navi 48 HDMI/DP Audio Controller'
class = multimedia
subclass = HDA
Note the PCI ids (1:0:0, 2:0:0, 3:0:0, 3:0:1). Yours may vary. Note that they may vary also when adding/removing cards from the system. My internal GPU from the Ryzen 5600G is at 3:0:0 & al when no PCI GPU is present, and at 14:0:0 & al when a PCI GPU. This caused a lot of grief during my tests.
Disregard the first two entries (1:0:0 and 2:0:0: PCI bridges on the card), they need be left alone, or the other two entries will not be accessible.
Configure the GPU passthru
In /boot/loader.conf, add passthru entries for the GPU and (optionally) the audio controller.
pptdevs="3/0/0 3/0/1"
Alternatively, you can tweak passthru devices without rebooting, using the devctl command-line utility, then make the setting permanent using the above loader configuration.
You also need the following in /boot/loader.conf:
# bhyve virtual machine monitor
vmm_load="YES"
# Enable AMD-Vi support / can only be tweaked at boot
hw.vmm.amdvi.enable="1"
Then reboot the host.
Run pciconf -lv again to check the GPU now shows up as ppt0, ppt1:
ppt0@pci0:3:0:0: class=0x030000 rev=0xc0 hdr=0x00 vendor=0x1002 device=0x7590 subvendor=0x1eae subdevice=0x8601
vendor = 'Advanced Micro Devices, Inc. [AMD/ATI]'
device = 'Navi 44 [Radeon RX 9060 XT]'
class = display
subclass = VGA
ppt1@pci0:3:0:1: class=0x040300 rev=0x00 hdr=0x00 vendor=0x1002 device=0xab40 subvendor=0x1002 subdevice=0xab40
vendor = 'Advanced Micro Devices, Inc. [AMD/ATI]'
device = 'Navi 48 HDMI/DP Audio Controller'
class = multimedia
subclass = HDA
Create a vm-bhyve environment
For easier day-to-day use of bhyve, I recommend the vm-bhyve package. It provides a command line interface similar to iocage for jails.
bhyve-firmware enables UEFI boot in bhyve.
tigervnc will be used as a VNC client to install Linux in the guest VM (this in turn subtly enables the UEFI option in the Debian installer). Run the following:
# pkg install vm-bhyve bhyve-firmware tigervnc-viewer
Then use the procedure documented in man vm. The following assumes the root path you chose for your bhyve environment is /vm, which is the default.
Create and install a Debian VM
Fetch and install an image of your favorite Linux distribution. I chose a network installation of Debian13 (https://www.debian.org/distrib/netinst).
As you will install AMD ROCm later to make use of the GPU, you may prefer a distribution which is supported by the ROCm installation instructions (see https://rocm.docs.amd.com/projects/install-on-linux/en/latest/install/post-install.html).
Place the Linux boot image in /vm/.iso/.
I highly recommend using the “UEFI” boot mode for the VM instead of the “grub loader mode”, as this avoids tedious grub configuration and potential incompatibilities from older grub versions.
Create the VM:
# vm create ollamavmExtend the created disk0.img file to a reasonable size. At least 50 GB are needed for a basic Debian 13 + ROCm + ollama, before downloading any model.
# truncate -s 100G /vm/ollamavm/disk0.imgEdit the VM config file in
/vm/ollamavm/ollamavm.confas follows. The most critical part is the GPU passthru configuration at the end.loader="uefi" # Adjust this to the number of CPUs you wish cpu=4 # Enable VNC access from host port 5900 graphics=YES # Enable better mouse positioning in VNC xhci_mouse=YES # RAM size. 16G is a bare minimum, 32G is better memory=32G network0_type="virtio-net" # Connect the ethernet port to the Bhyve network switch network0_switch="vm-public" network0_mac="58:9c:fc:0d:1c:83" # The disk size should be 50 GB minimum to install a minimal system + ollama. # Add required space to download models, or serve these via NFS disk0_type="virtio-blk" disk0_name="disk0.img" # Provided as an example/for the following two lines # leave the values created by vm create. uuid="42ff215d-d87f-11f0-bb66-244bfe8bca12" network0_mac="58:9c:fc:00:99:a5" # # GPU passthru # passthru0="3/0/0" passthru1="3/0/1" # # Use this instead if you need a particular PCI address for # the GPU to work # passthru0="3/0/0=3:0" # passthru1="3/0/1=3:1"
Install Linux
Run:
# vm isoto check for available install image names, then:
# vm install ollamavm $install_image_name(for example: $install_image_name = debian-13.2.0-amd64-netinst.iso)
Then start a VNC client to proceed with the Linux installation:
$ vncviewer 127.0.0.1:5900Install AMD ROCm in the Linux VM
Log-in to the Linux VM, then follow the ROCm installation instructions. This includes installing a more recent amdgpu driver than the stock Debian package:
https://rocm.docs.amd.com/projects/install-on-linux/en/latest/install/quick-start.html
Then reboot the Linux VM to load the new drivers.
Check the amdgpu driver successfully loads
dmesg output on a successful Linux boot, for reference purposes.
In some cases (for example, after using the GPU in another VM), the load may fail. In the case, rebooting the FreeBSD host may be needed to reset the GPU.
# dmesg -t | grep amdgpu
[drm] amdgpu kernel modesetting enabled.
amdgpu: Virtual CRAT table created for CPU
amdgpu: Topology: Add CPU node
amdgpu 0000:00:03.0: Invalid PCI ROM header signature: expecting 0xaa55, got 0x4556
amdgpu 0000:00:03.0: amdgpu: Fetched VBIOS from ROM
amdgpu: ATOM BIOS: 113-44TC6SHB1-P03
amdgpu 0000:00:03.0: amdgpu: Trusted Memory Zone (TMZ) feature not supported
amdgpu 0000:00:03.0: BAR 2 [mem 0x1010000000-0x10101fffff 64bit pref]: releasing
amdgpu 0000:00:03.0: BAR 0 [mem 0x1000000000-0x100fffffff 64bit pref]: releasing
amdgpu 0000:00:03.0: BAR 0 [mem 0x1000000000-0x100fffffff 64bit pref]: assigned
amdgpu 0000:00:03.0: BAR 2 [mem 0x1010000000-0x10101fffff 64bit pref]: assigned
amdgpu 0000:00:03.0: amdgpu: VRAM: 16304M 0x0000008000000000 - 0x00000083FAFFFFFF (16304M used)
amdgpu 0000:00:03.0: amdgpu: GART: 512M 0x0000000000000000 - 0x000000001FFFFFFF
[drm] amdgpu: 16304M of VRAM memory ready
[drm] amdgpu: 16050M of GTT memory ready.
amdgpu 0000:00:03.0: amdgpu: PCIE GART of 512M enabled (table at 0x0000008000000000).
amdgpu 0000:00:03.0: amdgpu: RAS: optional ras ta ucode is not available
amdgpu 0000:00:03.0: amdgpu: RAP: optional rap ta ucode is not available
amdgpu 0000:00:03.0: amdgpu: SECUREDISPLAY: securedisplay ta ucode is not available
amdgpu 0000:00:03.0: amdgpu: smu driver if version = 0x0000002e, smu fw if version = 0x00000032, smu fw program = 0, smu fw version = 0x00663e00 (102.62.0)
amdgpu 0000:00:03.0: amdgpu: SMU driver if version not matched
amdgpu 0000:00:03.0: amdgpu: SMU is initialized successfully!
snd_hda_intel 0000:00:03.1: bound 0000:00:03.0 (ops amdgpu_dm_audio_component_bind_ops [amdgpu])
amdgpu 0000:00:03.0: amdgpu: MES FW version must be >= 0x82 to enable LR compute workaround.
kfd kfd: amdgpu: Allocated 3969056 bytes on gart
kfd kfd: amdgpu: Total number of KFD nodes to be created: 1
amdgpu: Virtual CRAT table created for GPU
amdgpu: Topology: Add dGPU node [0x7590:0x1002]
kfd kfd: amdgpu: added device 1002:7590
amdgpu 0000:00:03.0: amdgpu: SE 2, SH per SE 2, CU per SH 8, active_cu_number 32
amdgpu 0000:00:03.0: amdgpu: ring gfx_0.0.0 uses VM inv eng 0 on hub 0
amdgpu 0000:00:03.0: amdgpu: ring comp_1.0.0 uses VM inv eng 1 on hub 0
amdgpu 0000:00:03.0: amdgpu: ring comp_1.1.0 uses VM inv eng 4 on hub 0
amdgpu 0000:00:03.0: amdgpu: ring comp_1.0.1 uses VM inv eng 6 on hub 0
amdgpu 0000:00:03.0: amdgpu: ring comp_1.1.1 uses VM inv eng 7 on hub 0
amdgpu 0000:00:03.0: amdgpu: ring sdma0 uses VM inv eng 8 on hub 0
amdgpu 0000:00:03.0: amdgpu: ring sdma1 uses VM inv eng 9 on hub 0
amdgpu 0000:00:03.0: amdgpu: ring vcn_unified_0 uses VM inv eng 0 on hub 8
amdgpu 0000:00:03.0: amdgpu: ring jpeg_dec uses VM inv eng 1 on hub 8
amdgpu 0000:00:03.0: amdgpu: Using BACO for runtime pm
[drm] Initialized amdgpu 3.61.0 for 0000:00:03.0 on minor 0
amdgpu 0000:00:03.0: [drm] fb1: amdgpudrmfb frame buffer device
Check GPU access is enabled in ROCm
Check rocminfo output. The following output shows 2 agents.
Agent 1 is the processor (Ryzen 5600G, which includes a minimal GPU — this seems to work by default, interestingly, no passthru is needed, but it is much slower than the GPU card).
Agent 2 is what matters: the GPU card. It may obviously show as agent 1 if your CPU doesn’t include a GPU. If the GPU card is not listed, most likely there is something wrong with the amdgpu driver and/or the passthru. Check the system boot logs (with dmesg). Use Linux lspci (the Linux equivalent to pciconf) to check the GPU shows up in the VM.
$ rocminfo
ROCk module is loaded
=====================
HSA System Attributes
=====================
Runtime Version: 1.18
Runtime Ext Version: 1.14
System Timestamp Freq.: 1000.000000MHz
Sig. Max Wait Duration: 18446744073709551615 (0xFFFFFFFFFFFFFFFF) (timestamp count)
Machine Model: LARGE
System Endianness: LITTLE
Mwaitx: DISABLED
XNACK enabled: NO
DMAbuf Support: YES
VMM Support: YES
==========
HSA Agents
==========
*******
Agent 1
*******
Name: AMD Ryzen 5 5600G with Radeon Graphics
Uuid: CPU-XX
Marketing Name: AMD Ryzen 5 5600G with Radeon Graphics
Vendor Name: CPU
Feature: None specified
Profile: FULL_PROFILE
Float Round Mode: NEAR
Max Queue Number: 0(0x0)
Queue Min Size: 0(0x0)
Queue Max Size: 0(0x0)
Queue Type: MULTI
Node: 0
Device Type: CPU
Cache Info:
Chip ID: 0(0x0)
ASIC Revision: 0(0x0)
Cacheline Size: 64(0x40)
Max Clock Freq. (MHz): 0
BDFID: 0
Internal Node ID: 0
Compute Unit: 4
SIMDs per CU: 0
Shader Engines: 0
Shader Arrs. per Eng.: 0
WatchPts on Addr. Ranges:1
Memory Properties:
Features: None
Pool Info:
Pool 1
Segment: GLOBAL; FLAGS: FINE GRAINED
Size: 32870884(0x1f591e4) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Recommended Granule:4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
Pool 2
Segment: GLOBAL; FLAGS: EXTENDED FINE GRAINED
Size: 32870884(0x1f591e4) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Recommended Granule:4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
Pool 3
Segment: GLOBAL; FLAGS: KERNARG, FINE GRAINED
Size: 32870884(0x1f591e4) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Recommended Granule:4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
Pool 4
Segment: GLOBAL; FLAGS: COARSE GRAINED
Size: 32870884(0x1f591e4) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Recommended Granule:4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
ISA Info:
*******
Agent 2
*******
Name: gfx1200
Uuid: GPU-22fb87b93c7f6339
Marketing Name: AMD Radeon RX 9060 XT
Vendor Name: AMD
Feature: KERNEL_DISPATCH
Profile: BASE_PROFILE
Float Round Mode: NEAR
Max Queue Number: 128(0x80)
Queue Min Size: 64(0x40)
Queue Max Size: 131072(0x20000)
Queue Type: MULTI
Node: 1
Device Type: GPU
Cache Info:
L1: 32(0x20) KB
L2: 4096(0x1000) KB
L3: 32768(0x8000) KB
Chip ID: 30096(0x7590)
ASIC Revision: 1(0x1)
Cacheline Size: 256(0x100)
Max Clock Freq. (MHz): 2840
BDFID: 24
Internal Node ID: 1
Compute Unit: 32
SIMDs per CU: 2
Shader Engines: 2
Shader Arrs. per Eng.: 2
WatchPts on Addr. Ranges:4
Coherent Host Access: FALSE
Memory Properties:
Features: KERNEL_DISPATCH
Fast F16 Operation: TRUE
Wavefront Size: 32(0x20)
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Max Waves Per CU: 32(0x20)
Max Work-item Per CU: 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 2147483647(0x7fffffff)
y 65535(0xffff)
z 65535(0xffff)
Max fbarriers/Workgrp: 32
Packet Processor uCode:: 962
SDMA engine uCode:: 86
IOMMU Support:: None
Pool Info:
Pool 1
Segment: GLOBAL; FLAGS: COARSE GRAINED
Size: 16695296(0xfec000) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Recommended Granule:2048KB
Alloc Alignment: 4KB
Accessible by all: FALSE
Pool 2
Segment: GROUP
Size: 64(0x40) KB
Allocatable: FALSE
Alloc Granule: 0KB
Alloc Recommended Granule:0KB
Alloc Alignment: 0KB
Accessible by all: FALSE
ISA Info:
ISA 1
Name: amdgcn-amd-amdhsa--gfx1200
Machine Models: HSA_MACHINE_MODEL_LARGE
Profiles: HSA_PROFILE_BASE
Default Rounding Mode: NEAR
Default Rounding Mode: NEAR
Fast f16: TRUE
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 2147483647(0x7fffffff)
y 65535(0xffff)
z 65535(0xffff)
FBarrier Max Size: 32
ISA 2
Name: amdgcn-amd-amdhsa--gfx12-generic
Machine Models: HSA_MACHINE_MODEL_LARGE
Profiles: HSA_PROFILE_BASE
Default Rounding Mode: NEAR
Default Rounding Mode: NEAR
Fast f16: TRUE
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 2147483647(0x7fffffff)
y 65535(0xffff)
z 65535(0xffff)
FBarrier Max Size: 32
*** Done ***
Install ollama
Then install and start ollama, see:
Et voilà! Enjoy!
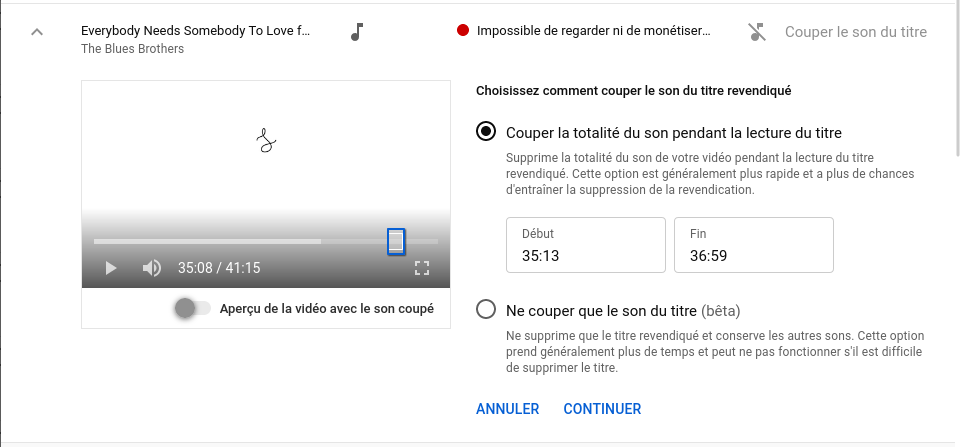
PS, the result: