
En raison de l’actualité — révision de la loi renseignement de 2015 –, on parle à nouveau des boites noires, dispositifs que les services de renseignement ont souhaité installer dès 2015 sur Internet dans l’espoir d’opérer un équivalent des écoutes téléphoniques.
Ce billet se veut une réflexion purement théorique sur les aspects juridiques et possibilités techniques des boites noires [pour les aspects techniques réels voire a-légaux, on peut se référer à cet article de Reflets sur IOL et j’y reviendrai peut-être ; pour le juridique, à cet article très détaillé de Félix Tréguer].
Les boites noires ont été créées, au titre de la loi renseignement votée en juillet 2015, par l’article L851-3 du code de la sécurité intérieure. Extrait :
il peut être imposé aux opérateurs et aux personnes mentionnés à l’article L. 851-1 la mise en œuvre sur leurs réseaux de traitements automatisés destinés, en fonction de paramètres précisés dans l’autorisation, à détecter des connexions susceptibles de révéler une menace terroriste.
Le législateur ne dit rien ici des moyens à mettre en œuvre. En théorie, il peut s’agir de traitements purement logiciels — utilisant donc les moyens existants de l’opérateur –, ou de matériel dédié à cet usage — ce que l’on entend en général par “boites boires” –.
C’est la CNCTR (Commission nationale de contrôle des techniques de renseignement) qui se charge de la mise en œuvre administrative des boites noires : procédures d’autorisation, etc.
La CNCTR et l’« algorithme »
Dans le rapport d’activité 2019 de la CNCTR, les « boites noires » sont plaisamment baptisées « technique de l’algorithme ». On peut lire page 51 :
“S’agissant enfin de l’algorithme52 sur des données de connexion en vue de détecter des menaces terroristes, aucune nouvelle autorisation de mise en œuvre n’a été sollicitée en 2019. À la fin de l’année 2019 trois algorithmes avaient été autorisés depuis l’entrée en vigueur du cadre légal et continuaient à être en fonctionnement.”
52 – Il s’agit de la technique prévue par les dispositions de l’article L. 851-3 du code de la sécurité intérieure.
À ce stade, avec 3 mises en œuvre en 2019, le déploiement des boites noires semble assez limité. Dans son rapport 2020 qui vient tout juste d’être publié, la CNCTR affirme que rien n’a changé cette année-là : ces mêmes 3 boites noires sont toujours en place.
Malgré de nombreux débats et questions au parlement lors de leur vote, on ne sait rien sur leurs capacités physiques, ni sur les données et algorithmes utilisés, ni sur les emplacements choisis. La raison invoquée est le secret défense.
Sous le capot : les données de connexion
Un rapide détour technique s’impose. Si cela vous ennuie, vous pouvez passer directement à la section suivante.
C’est un document technique, la RFC 791, qui a défini le format des informations échangées sur Internet, autrement le paquet IPv4 (je ne parlerai pas ici du paquet IPv6, mais les principes sont les mêmes). C’est son entête qui contient l’intégralité des données de connexion réellement utilisées par le fournisseur d’accès. On parle aussi de métadonnées. Surlignées en vert, les données indispensables à l’acheminement du paquet : l’adresse source et l’adresse destination. En orange, d’autres données également utiles à l’acheminement. En jaune, on commence à entrer dans les détails des données transmises : il ne s’agit plus vraiment de données de connexion au sens strict.
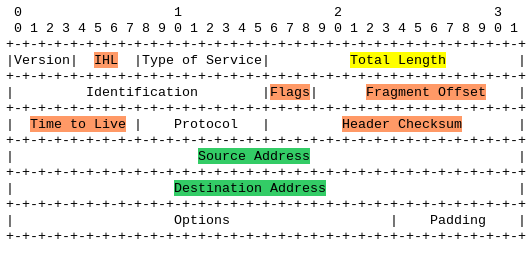
La RFC 793, quant à elle, définit les informations de l’entête TCP, qui est utilisé notamment pour les connexions http (web), et vient s’ajouter aux données IP précédentes.
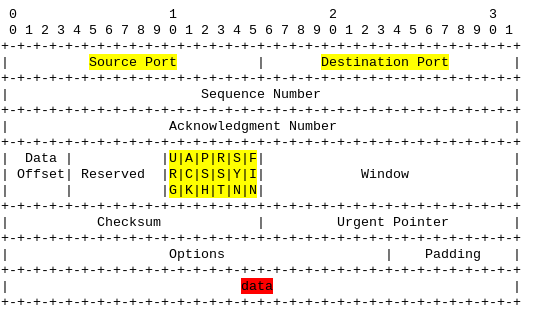
TCP définit le port source et le port destination (ici en jaune) : ils permettent en particulier de distinguer une connexion web (port 80 ou 443) d’une connexion de courrier électronique (25, 143, 993, 587, etc, suivant le cas). TCP transporte également les données utiles — l’intérieur de l’enveloppe –, c’est le “data” en rouge en bas du paquet.
L’inspection profonde, ou DPI
On appelle Deep Packet Inspection (DPI), en français « inspection de paquets », l’accès aux données au delà des données de connexion. C’est un procédé beaucoup plus intrusif, et qui sort du cadre de ce qui est permis par la loi même au titre des boites noires.
En matière postale, cela reviendrait à ouvrir une enveloppe pour en lire le contenu, ce qui est formellement prohibé (secret des correspondances).
Le terme de DPI éveille donc l’attention lorsqu’il est utilisé.
Que sont les boites noires et où les met-on ?
Ce point à lui seul mériterait un billet complet. Les questions à se poser sont, notamment :
- les boites noires contiennent-elles des moyens de stockage ?
- où sont-elles placées : sur les dorsales de réseaux, aux points d’échange, aux points de raccordement des abonnés, chez les hébergeurs, sur des liens internationaux… liste non exhaustive et non exclusive ?
- quelles informations pré-triées remontent-elles aux services de police ?
- quels traitements sont réalisés, dans la boite noire et après celle-ci, sur les informations ?
La nouvelle loi et l’accès aux URL…
D’après Gérald Darmanin reçu par France Inter le 28 avril 2021, la nouveauté sera l’accès aux URL : « La difficulté que nous avions, c’est que nous n’utilisions pas les URL. Là vous utilisez les URL, c’est à dire les données de connexion qui vous permettent de voir quelle recherche exacte vous faites. » (émission ici).
[Mise à jour : Il invoque ensuite — et c’est un sujet légèrement différent, mais connexe et plus inquiétant — la collaboration des plateformes pour accéder à nos messages chiffrés et possiblement aux journaux de connexion, qui permettent de savoir les URL consultées.]
… et pourquoi ce n’est pas si simple qu’à la radio ou au parlement
Cela pose deux problèmes : un de principe, et un technique.
Le problème de principe est simple : l’URL est transportée uniquement dans la partie data des paquets. Si on se limite aux données de connexion, comme l’exige actuellement la loi, il est impossible d’y accéder. En fait, la loi interdit même, en théorie, à la police de distinguer une connexion web d’une connexion de courrier électronique ou d’une requête DNS, puisqu’il faut regarder les numéros de ports, et que ceux-ci ne relèvent pas à strictement parler des données de connexion au sens du fournisseur d’accès.
Pour accéder aux URL, il faut donc exploiter du DPI, mentionné plus haut.
Admettons donc qu’une analyse complète du paquet par DPI soit permise juridiquement.
Aujourd’hui, 80 % des communications de données sur Internet sont chiffrées. C’est ce qu’indique le cadenas dans votre navigateur, désormais présent sur presque tous les sites. [Correction : @cryptopartyrns sur twitter m’indique qu’en 2021 on est plutôt autour des 90-95 %]
Or, il est impossible d’accéder à ces données de manière instantanée. Au mieux, il faut dépenser des semaines ou mois de calcul intensif pour casser le chiffrement (décrypter). C’est évidemment impossible à réaliser sur une proportion significative du trafic Internet : ce type de décryptage, coûteux et lent, n’est effectué que dans des cas rares et limités.
La CNIL dans sa délibération du 8 avril 2021 confirme d’ailleurs que seule l’écoute des URL “en clair” est envisagée à ce stade :

Le chiffrement ne protège pas toutes nos communications
Sans casser le chiffrement, il existe encore plusieurs failles à la confidentialité de notre trafic :
- les adresses IP source et destination, nécessaires pour acheminer le trafic.
- les numéros de ports utilisés, qui donnent des indices sur l’activité (web, mail, etc).
- le DNS, qui circule encore largement en clair aujourd’hui, même si DoH et DoT visent à mettre fin à cette faille. En écoutant le DNS, il est possible de savoir le nom du site auquel quelqu’un accède. Si le site est youtube.com ou facebook.com, cela ne va pas nous en apprendre autant sur le contenu que s’il s’agit de openrailwaymap.org.
- le chiffrement web, appelé TLS, ne chiffre pas encore le nom du site demandé. On peut donc le connaître également par ce biais. C’est en cours de résolution avec une extension appelée ESNI, dont le déploiement est balbutiant.
- il existe aussi des failles occasionnelles de sécurité permettant de casser plus rapidement du trafic chiffré. Ces failles sont évidemment corrigées après leur découverte, et tout est fait pour les éviter. Leur exploitation ne peut être qu’aléatoire et temporaire, il n’est pas possible de fonder une stratégie d’écoutes sur elles.
- il y a enfin la possibilité d’émettre des faux certificats pour écouter le trafic. Ce type d’intervention n’est cependant pas discret, il ne peut donc pas être utilisé à grande échelle sous peine d’être rapidement découvert.
L’existence de très grandes plateformes rend la connaissance du nom de serveur de moins en moins utile : personne ne peut savoir par ce simple nom si la vidéo Youtube ou la page Facebook que je consulte sont celles d’un groupe faisant l’apologie du terrorisme ou d’un club de fondamentalistes des chatons.
Il existe un dernier moyen, plus aléatoire mais plus rapide, de découvrir quel contenu chiffré a été accédé : la connaissance de la quantité de données transférées. Si j’accède sur nextinpact.com ou partipirate.org à une page de 367813 octets, il est relativement facile à partir de cette simple information de retrouver de quelle page il s’agit à partir d’un index du site, tel que les moteurs de recherche peuvent en posséder. Là aussi, des contre-mesures sont envisageables dans le futur proche (bourrage de paquets, ou padding).
Déterminer quelle vidéo a été consultée à partir de la taille transmise est plus difficile, les retours en arrière ou visionnages partiels étant fréquents. En revanche, on peut tenter d’estimer le débit de la vidéo, voire le passage visionné, à partir des intervalles temporels et des tailles de paquets.
L’intelligence artificielle peut-elle aider Gérald Darmanin ?
Probablement : non.
Je suppose que l’on parle ici de la technique particulière de l’apprentissage profond (réseaux neuronaux). L’effet de mode étant patent, le terme d’IA utilisé en tant que poudre de perlimpinpin, comme le secret défense, permet de se dispenser d’argumentation.
Or l’intelligence artificielle — comme l’informatique — a besoin, pour fonctionner, de données concrètes et ne peut pas deviner des données non accessibles, par exemple chiffrées, qui sont majoritaires dans l’Internet d’aujourd’hui.
Supposons malgré cela qu’on ait des données suffisamment « en clair ».
L’intelligence artificielle a en outre besoin d’une quantité suffisante de données : un jeu de données initial, de préférence aussi étendu que possible, fourni avec les « réponses ». Dans le cas de l’apprentissage lié aux boites noires, puisque nous voulons déclencher, ou ne pas déclencher, des alarmes appelant à une investigation plus poussée, il faudrait donc les données suivantes :
- des données de connexion anodines ne devant pas déclencher d’alarme
- des données de connexion de présumés terroristes déclenchant l’alarme
Si l’ensemble 1 ne pose pas de problème technique pour être obtenu en volume, l’ensemble 2 est moins simple : il existe heureusement peu de terroristes, on ne dispose donc pas a priori de beaucoup de données de connexion en rapport, et les signaux à repérer vont varier dans le temps : nouveaux sites, nouveaux contenus, nouvelles applications.
L’usage de l’intelligence artificielle pour détecter des terroristes ne semble pouvoir mener qu’à une impasse également : les données d’apprentissage ont toutes les chances d’êtres insuffisantes, la cible est rare, et la combinaison de ces deux facteurs va donc produire une quantité élevée de faux positifs. Tous les systèmes de « détection automatique de terroristes » ont ce même problème statistique.
Comment réagir ?
Il est établi que l’accès aux URL n’est pas possible avec le degré et l’utilité que laissent entendre les déclarations de Gérald Darmanin.
Concernant l’usage de l’intelligence artificielle, le ministre cherche manifestement à développer l’industrie des technologies de surveillance par de la subvention déguisée. Autrement dit : chacun sait que cela ne peut pas marcher, mais cela permet d’attribuer de la commande publique à des sociétés bien choisies. Cette intention de soutenir l’industrie de la surveillance a déjà été explicitée par le gouvernement, notamment lors des discussions sur la reconnaissance faciale.
Il est probable que la loi ne va pas changer grand chose à l’efficacité des boites noires. Si la disposition permettant l’accès aux URL est adoptée, elles vont devenir plus intrusives : l’accès au delà des données de connexion est un précédent et supprime une protection notable. Il faut donc nécessairement le refuser, en tant que position de principe.
Mais l’impact de ce renoncement est fortement atténué par le déploiement du chiffrement suite aux révélations d’Edward Snowden concernant la surveillance de masse.
Nous devons donc continuer à privilégier les outils chiffrés de bout en bout, et les informaticiens à les déployer et les développer (je pense à la protection des noms de domaine). Fondés sur les mathématiques plutôt que sur les intentions de nos gouvernants et de nos polices, ils restent le meilleur moyen à ce stade de nous protéger des intrusions à grande échelle dans nos communications personnelles et notre vie privée.
Quant aux intentions exprimées par Gérald Darmanin sur la collaboration des plateformes pour accéder à nos contenus chiffrés en passant par la petite porte, elles sont à suivre avec une grande attention, car elles constituent une autre forme notable d’extension de la surveillance, d’autant plus inquiétante qu’il n’y a jamais de retour en arrière (effet cliquet).
De nombreuses fictions télévisuelles font référence à des communications illégitimes faites dans des jeux vidéo. Or, ces derniers ne sont pas spécialement sécurisés. En outre, si leur trafic n’est pas majoritaire, il n’en demeure pas moins à considérer : les trafics web et les messageries instantanées classiques ne sont pas les seuls moyens de communication.
Il y a une légère erreur dans le lien vers l’article de Reflets 🙂
Ah oui en effet. Corrigé, merci 🙂
Du coup, c’est le lien vers l’article de Félix Tréguer qui est cassé 😉