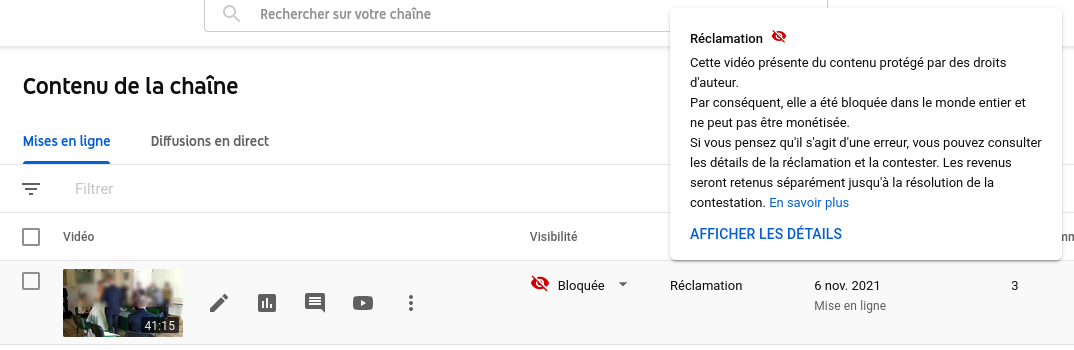
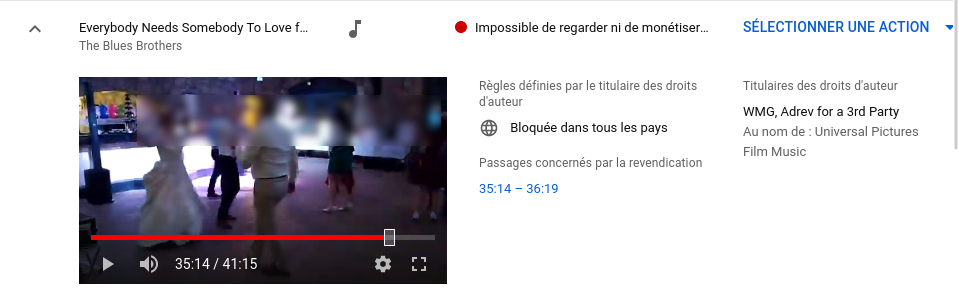
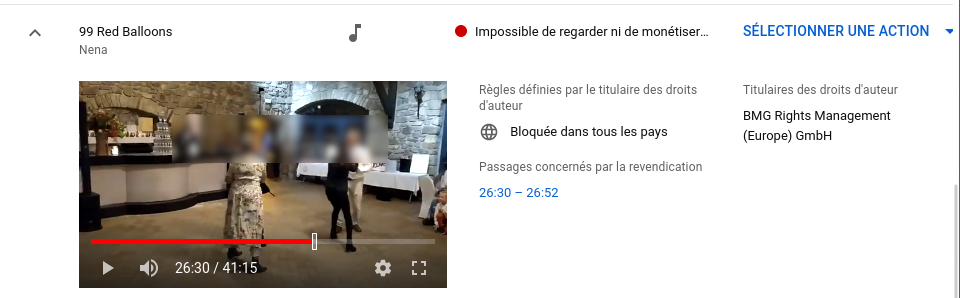
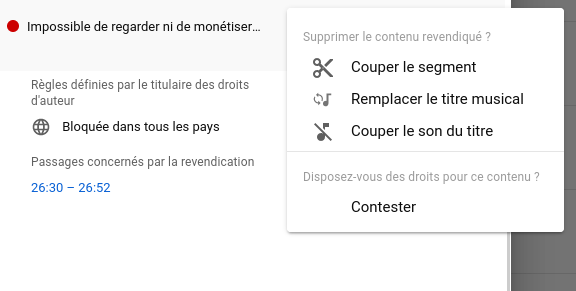
Un point sur la directive copyright semble utile (j’avais écrit ici une petite introduction précédemment, pour les lecteurs qui ne sont pas au courant de l’article 13 de cette directive).
La nouvelle du jour, c’est qu’après des mois de tergiversations, la position française (totalement acquise aux ayants-droit) semble avoir eu gain de cause, ce qui est inquiétant. Les garde-fous demandés par les défenseurs des libertés en ligne semblent avoir été largement ignorés.
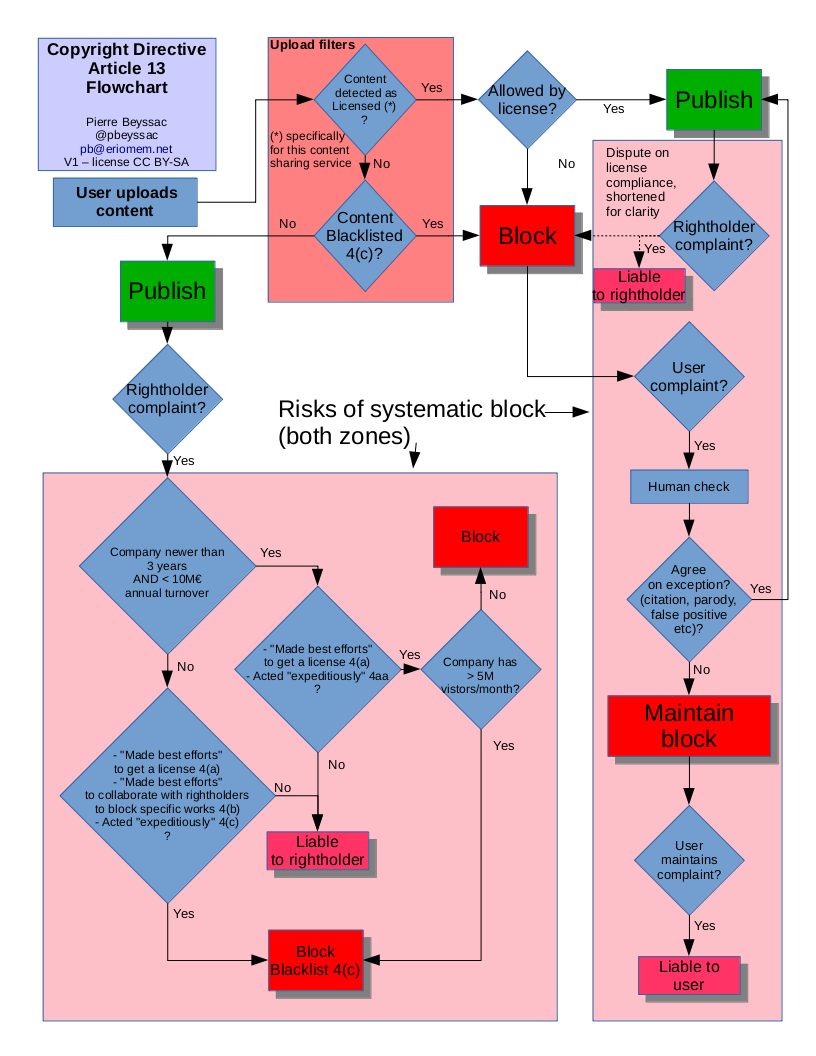
Ainsi, ni PME ni les sites à but non lucratif (ce dernier point ne semble pas certain, mais ce n’est pas encore très clair) ne seraient exclus du champ de l’article 13, ce qui revient à mettre une barrière d’entrée infranchissable à ceux-ci en face des GAFAM puisque ces derniers disposent déjà des technologies de filtrage nécessaires pour être à l’abri de l’article. Et il risque d’en résulter une censure sans subtilité des contenus produits par les utilisateurs, voire disparition pure et simple (ou inexistence) de certains services (voir ici le tout dernier article de Julia Reda, députée européenne allemande, pour les détails).
Revenons sur les facteurs qui font que la position française en la matière est particulièrement extrémiste.
Les institutions françaises et les ayants-droit
Sans revenir en détail sur la situation française autour de l’exception culturelle, un peu de contexte est nécessaire.
Depuis des décennies, la concrétisation de l’exception culturelle est le passage de lois de protection de l’industrie du spectacle, éventuellement au détriment de l’intérêt public.
Il y a ainsi eu les lois cherchant à protéger le cinéma contre la télévision (chronologie des médias), puis le cinéma et la télévision contre la cassette VHS et le DVD, puis les chaînes privées brouillées, puis la VHS et le DVD contre les importations contrariant les exclusivités nationales, puis le CD contre la musique en ligne, puis tout cela contre le piratage. Cette liste n’est, bien sûr, pas exhaustive (des séries de lois similaires existent concernant le livre).
S’y ajoutent les diverses taxes et redevances destinées à soutenir la même industrie : redevance télévisuelle (dont une bonne partie sert à acquérir des droits de diffusion), redevance copie privée (supposée dédommager les ayants-droit pour les copies de sauvegarde des œuvres que vous avez légalement acquises, mais que vous paierez également pour stocker vos vidéos de vacances ou en achetant votre téléphone), droits divers sur votre abonnement Internet, etc.
S’y ajoutent un certain nombre d’instances et d'”autorités administratives indépendantes”, suivant le terme consacré : la Hadopi et le CSA, mais aussi le CSPLA (conseil supérieur de la propriété littéraire et artistique) ou la commission pour la rémunération de la copie privée, qui décide unilatéralement du montant de la redevance copie privée. Toutes ces entités dépendent du ministère de la culture.
Une des missions principales attribuées au ministère de la culture est de réaliser, au niveau français, la législation pour protéger les ayants-droit, et à l’échelle européenne, le lobbying pour légiférer dans le même but, en particulier la directive copyright (dite “directive droit d’auteur” en France) qui nous intéresse en ce moment.
Officiellement, la mission du ministère est de « rendre accessibles au plus grand nombre les œuvres capitales de l’humanité et d’abord de la France ». En pratique, cette mission est interprétée de manière limitative : ne comptez pas sur le ministère pour défendre les licences libres ou le domaine public, car il s’agit d’un casus belli vis-à-vis des industries littéraires et du spectacle, et celles-ci l’ont clairement exprimé à plusieurs reprises.
Enfin, ce panorama ne serait pas complet sans un mot sur la représentation française au parlement européen : elle a été à l’avenant lors du vote de juillet, dans une écrasante majorité en faveur des ayants-droit, sans nuance et tous partis confondus, à l’exception notable des Verts.
Les médias et les ayants-droit
La couverture par les médias généralistes en France de la directive copyright a été quasiment inexistante, sinon pour :
- accorder des tribunes aux ayants droit, pour défendre l’utilité de l’article 13, en en ignorant les effets néfastes ;
- s’indigner du lobbying — réel — de Youtube et Google contre la directive, en oubliant totalement que les ayants-droit ne sont pas en reste, loin de là, en matière de lobbying ; et qu’au delà de ces 2 lobbies bien visibles et d’un storytelling binaire mais facile, devrait être évoqué l’intérêt général, celui des citoyens.
En ce qui concerne la presse, la directive prévoit l’article 11, censé obliger les moteurs de recherche à rémunérer les journaux pour le trafic que les premiers leur apportent. Pour en arriver à cette absurdité (qui équivaut à demander une commission à un taxi pour qu’il ait le droit de déposer ses clients à tel hôtel), il faut tordre le droit d’auteur et les usages d’Internet, en piétinant le droit de citation.
Les lobbyistes des articles 11 et 13 sont donc entrés depuis l’été 2018 dans un jeu de donnant-donnant. « Je soutiens ton article 11, en échange tu soutiens mon article 13, et réciproquement ». En effet, le sort de ces deux articles est lié : l’un comme l’autre visent clairement Internet sous couvert de cibler les GAFAM ; l’un comme l’autre sont contestés depuis des mois par les associations de défense des libertés ; et le reste de la directive copyright est relativement consensuel.
Ainsi, les tenants de l’article 11 (la presse) se sont vu reprocher par ceux de l’article 13 (les ayants-droit de l’industrie du spectacle) l’échec du vote de juillet 2018, qui aurait permis une validation accélérée au parlement européen, en donnant mandat au rapporteur Axel Voss pour terminer l’écriture de la directive.
Autrement dit, le sort de la directive copyright repose essentiellement sur le consensus qui sera obtenu sur ces articles 11 et 13 ; et cela traîne, car la position française, totalement calquée sur les demandes des ayants-droit, est loin de faire l’unanimité dans l’Union Européenne.
En France, le sujet ne suscite guère d’intérêt médiatique sinon pour s’indigner épisodiquement de manière pavlovienne de l’hégémonie des GAFAM, comme dans cette récente édition de l’Instant M de France Inter qui, toute occupée à dénoncer l’activisme de Youtube, en oublie accessoirement celui des ayants-droit, mais surtout arrive à faire l’impasse sur le sujet de la liberté d’expression, ce qui est plus gênant.
Précisons que je n’ai rien contre cette émission. C’est simplement l’exemple le plus récent auquel j’ai été confronté, mais il en existe bien d’autres, dans le Monde, dans Les Échos, et ailleurs, sous forme, souvent, de tribunes d’opinion à des collectifs d’artistes, ou d’interviews d’artistes en vue. Ainsi, pour ne citer que Jean-Michel Jarre, dès les titres, la tonalité est claire :
- Le Monde : Jean-Michel Jarre : « YouTube ne doit pas devenir un monopole »
- France Info : Jean-Michel Jarre défend les auteurs face aux “monstres d’internet”
On cherchera en vain des articles aussi médiatisés exprimant des positions allant clairement contre les articles 11 et 13 de la directive, ceux-ci étant essentiellement du ressort de la presse spécialisée, ou relégués dans des rubriques “actualité numérique”.
Il faut quand même noter quelques exceptions. J’ai eu la chance et l’honneur d’être sollicité par France 24 pour défendre le point de vue des utilisateurs et hébergeurs Internet, ainsi que pour des articles de BFMTV et Marianne, ce dont je les remercie. J’ai également été invité par l’April à l’émission Libre à vous sur Radio Cause Commune, qui est revenue à plusieurs reprises sur la directive. Enfin, on ne peut oublier la couverture régulière de ces sujets, et de tout ce qui concerne le lobbying numérique des ayants-droit, dans Nextinpact, sous la plume de Marc Rees.
La situation associative française
Plus préoccupant, et plus surprenant, l’une des associations phares de défense des droits numériques en France, la Quadrature du Net, a fait preuve d’un mutisme quasi complet sur le sujet de la directive, hors quelques déclarations de principe contre l’article 13 jusqu’à l’été 2018, suivies de prises de positions niant le danger de la directive pour l’« Internet libre », totalement à contre-courant du sentiment général dans les associations similaires.
La Quadrature n’a pas jugé possible non plus de prendre le temps de signer la lettre ouverte d’EDRI, au contraire de 90 des associations européennes et internationales les plus en vue se préoccupant de droits numériques, dont l’EFF états-unienne.
C’est d’autant plus ennuyeux que la Quadrature du Net dispose, dans le domaine associatif numérique, d’un historique et d’une écoute médiatiques qui n’ont guère d’équivalent en France. Son absence peut en partie expliquer la couverture médiatique univoque observée sur le sujet.
On note un autre absent de marque, le Conseil National du Numérique, qui semble se cantonner désormais aux missions que lui confie le gouvernement Macron.
Les deux principales associations françaises ayant réellement fait campagne contre la directive sont l’April, association de défense du logiciel libre, et Wikimédia, la branche française de la fondation qui édite le bien connu Wikipédia, concerné directement par les articles 11 et 13. On peut citer également le CNLL et Renaissance Numérique parmi les signataires de la lettre ci-dessus.
Un article 13 extrême
Même parmi les ayants-droit, l’article 13 ne faisait pas l’unanimité. Ainsi, en décembre, des ayants-droit du cinéma et du sport se sont désolidarisés de l’article tel qu’il était rédigé, estimant qu’il allait trop loin et ne bénéficierait qu’aux grandes plateformes. C’est également la position des associations.
Un résultat à la hauteur des efforts français
Comme précisé plus haut, il semble qu’après un combat entre la position française et celle d’autres pays, dont l’Allemagne, la directive copyright soit en train de passer avec un article 13 in extenso, minimaliste vis-à-vis de la protection des droits des citoyens et des intermédiaires techniques, la position de la France ayant prévalu. Rien n’étant jamais gratuit dans ces négociations, difficile de dire contre quel abandon réciproque la défense des ayants-droit a été troquée vis-à-vis de l’Allemagne.
Une situation plombée
En France, comme on l’a vu, la situation politique est verrouillée depuis des décennies par les ayants-droit, au détriment de l’intérêt général, et sans espoir ni même volonté d’en sortir.
Par parenthèse, car le domaine de la SVOD (vidéo par abonnement en ligne) est très anecdotique au regard des impacts potentiels des articles 11 et 13, le prochain échec sera celui d’un concurrent potentiel à Netflix, coulé d’avance par une législation et un écosystème hexagonaux hostiles à toute innovation en la matière, et une absence de vision. Ainsi, après avoir plombé molotov.tv par l’accumulation de règles sur les magnétoscopes virtuels, après le quasi échec de Canal Play qui en est réduit à imposer des procédures de désabonnement compliquées pour retenir ses abonnés (on notera que Vivendi n’a pas voulu acquérir Netflix à ses débuts), on nous prépare salto.fr, sur fonds publics, qui croit pouvoir s’imposer par des exclusivités sur les séries de France Télévision (celles-ci seront retirées de Netflix), et qui, inévitablement, rejoindra quelques temps après son ouverture la longue liste de nos échecs de stratégie industrielle et politique.
Et maintenant ?
La première chose à faire, urgente et essentielle, serait de sortir du raisonnement mortifère (et réactif) « ce qui est mauvais pour les GAFAM est bon pour l’intérêt général » qui actuellement motive et oriente l’essentiel de l’action législative française en matière numérique.
D’une part, parce que ce qui semble mauvais pour les GAFAM ne l’est pas forcément réellement pour eux. Ainsi, Google/Youtube dispose déjà de la technologie nécessaire pour appliquer l’article 13, ce qui lui donne une avance considérable sur le reste de l’industrie. Ensuite, on a appris récemment que Facebook, derrière une opposition de façade à l’article 13, poussait discrètement le législateur à l’adopter, parce que Facebook possède également une avance technologique en la matière.
D’autre part, ce qui semble mauvais pour les GAFAM, a, a priori, des chances de l’être également pour des acteurs similaires, les hébergeurs et autres intermédiaires techniques, qu’ils soient à but lucratif ou non, et Wikimédia l’a bien compris. Difficile de se plaindre de la prééminence persistante des GAFAM lorsqu’on a savonné également la planche des services concurrents, à moins que le plan soit de renforcer cette prééminence pour avoir un lieu de contrôle, surveillance et taxation centralisé plus simple à gérer par les états.
Dans un autre registre, on voit déjà dans les tentatives de taxation de Google et Facebook par l’état français que le crayon du législateur peut déborder : il suffit qu’un article de loi soit mal rédigé pour qu’il ait un impact bien au delà de Google ; la loi étant supposée ne pas viser un acteur particulier, ce qui serait discriminatoire, elle doit établir des principes, mais les acteurs similaires (dans le monde publicitaire en particulier) existent et, s’ils sont probablement ravis qu’on taxe Google, ils souhaiteraient éviter qu’on les taxe pour la même activité.
Il suffit de transposer la situation fiscale à celle des articles 11 et 13 pour imaginer les dangers vis-à-vis de la liberté d’expression.
Ensuite, parce que se focaliser sur la lutte contre les GAFAM revient à négliger les citoyens. Ceux-ci auraient du mal à migrer en masse vers d’autres services, même si cela pourrait être souhaitable, à supposer que de tels services existent. Notamment, restreindre par la loi la liberté d’expression sur les GAFAM, même si elle n’y est pas parfaite, revient à restreindre la liberté d’expression tout court.
Enfin, la loi doit poser des principes généraux et fonctionner le moins possible par exceptions. Ainsi, l’article 13 prévoit une liste limitative d’exceptions, qui correspondent à des services déjà existants. Mais l’imagination des développeurs de sites et d’applications est plus fertile que celle du législateur et des lobbies du moment, et les possibilités d’Internet plus larges. Ainsi, si les forges de logiciel ou les encyclopédies en ligne n’existaient pas déjà, avec des acteurs de taille notable pour les défendre, les exceptions correspondantes auraient été tout simplement oubliées.
À côté de quels autres services et usages encore inconnus sommes-nous en train de passer en écrivant la loi contre les acteurs hégémoniques du moment et pour soutenir tel ou tel groupe d’intérêt sur des modèles d’un autre temps qui, tôt ou tard, devront être repensés en fonction des possibilités de la technologie, et non contre celle-ci ?
Et pour revenir à la liberté d’expression : elle est — en partie — incluse dans le paragraphe qui précède, dans ces futurs services, même si elle mériterait un développement. Rappelez-vous du Minitel, un modèle qui a eu son heure de gloire, mais très encadré à tous points de vue, et en particulier pour préserver le modèle de la presse papier. Pensez-vous vraiment que la liberté d’expression y était aussi étendue que sur Internet aujourd’hui ?
Et plus largement, les attaques récentes contre l’anonymat en ligne par le gouvernement, beaucoup de politiques même dans l’opposition, et certains syndicalistes et éditorialistes montrent que la position de la France sur les articles 11 et 13 est loin d’être un accident de parcours.