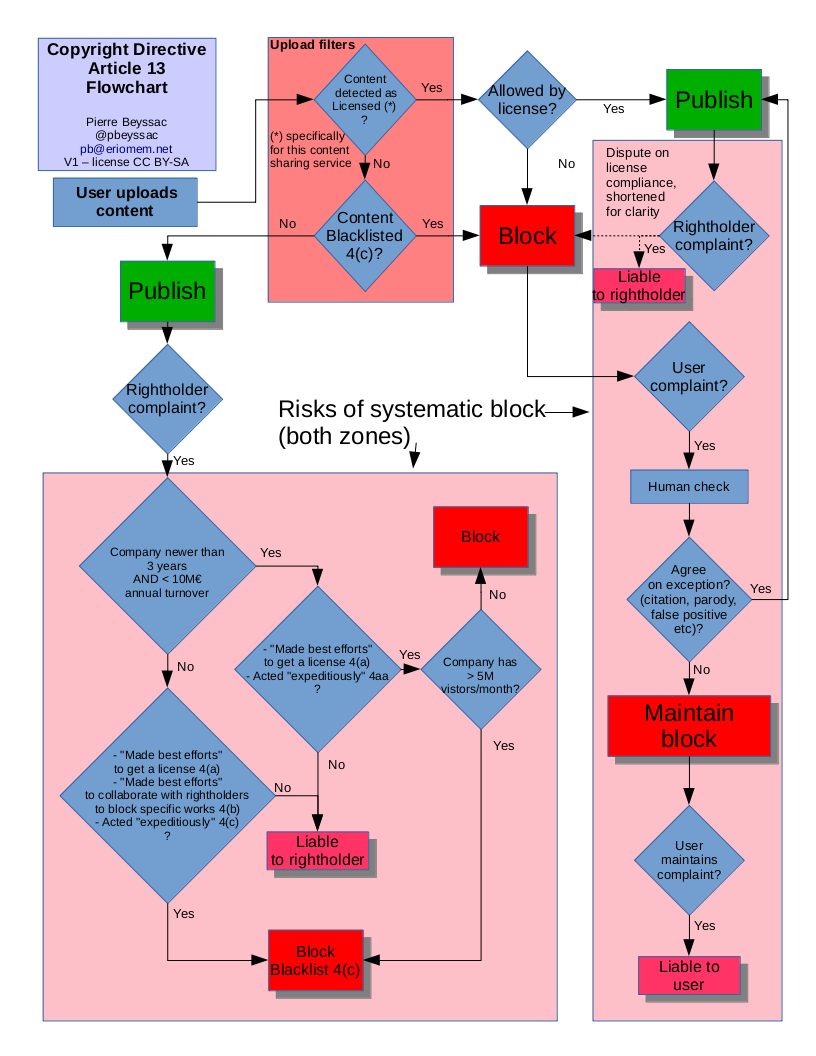
Avertissement ajouté le 17/7/2020 : l’objet de ce billet n’est pas de nier l’impact environnemental du numérique, mais d’étudier la pertinence des injonctions à la limitation de notre volume de données.
La facturation au volume, ou la limitation des abonnements Internet, vieux serpent de mer des réseaux numériques depuis des décennies et rêve de certains opérateurs, fait aujourd’hui sa réapparition sous la motivation de la défense de l’environnement, notamment via un rapport récent du sénat, suivi d’un rapport similaire du Conseil national du numérique. Ces rapports s’appuient notamment sur ceux du Shift Project de 2018 et 2019 sur la sobriété numérique ; ces derniers ont vu certains de leurs éléments critiqués en raisons d’erreurs manifestes (surévaluations des empreintes).
Suite à de nombreuses discussions notamment sur les réseaux sociaux, lectures de rapports et études, etc, depuis 2 ans, je voulais poser ici quelques arguments mis en forme pour éviter d’avoir à les réécrire ici et là.
L’affirmation principale qui sous-tend l’idée de limiter notre consommation de données est que l’explosion des volumes provoquerait une explosion de la consommation électrique. Cet argument est également cité pour mettre en doute la pertinence du déploiement de la 5e génération (5G) de téléphonie mobile.
Nous allons voir qu’en fait, l’essentiel de la consommation électrique des réseaux est constitué par le fonctionnement de l’infrastructure, indépendamment de la quantité de données.
Si vous n’avez pas envie de lire les détails de ce billet, vous pouvez vous contenter de “Et le réseau mobile” et “Faut-il vraiment réduire notre consommation de données ?”, en complétant si nécessaire par “La puissance et l’énergie” pour les notions d’électricité.
La puissance et l’énergie
Pour commencer, quelques rappels de notions électriques fondamentales pour mieux comprendre les chiffres que l’on voit circuler ici et là, et leurs ordres de grandeur.
Le Watt est l’unité de puissance électrique. C’est une valeur “instantanée”. Pour éclairer correctement vos toilettes, vous aurez besoin de moins de puissance que pour illuminer un monument comme la tour Eiffel. Un four électrique, un grille pain ou un radiateur engloutissent aux alentours de 1500 à 2500 watts. Un téléphone mobile, moins de 5 watts. Comme la quasi totalité de la consommation électrique passe en effet Joule, tout objet usuel qui consomme de manière significative émet de la chaleur. C’est un moyen très simple de s’assurer qu’un objet ne consomme pas beaucoup d’électricité : il ne chauffe pas de manière sensible (c’est un peu différent pour des moteurs électriques, mais cela reste vrai pour des ampoules).
Le Watt.heure, Wh (ou son multiple le kilowatt.heure, kWh) est une unité d’énergie. Si vous vous éclairez pendant 2 heures au lieu d’une heure, la consommation d’énergie sera doublée. Et en mettant deux ampoules, vous consommerez en une heure ce qui aurait pris deux heures avec une simple ampoule.
Le fournisseur d’électricité compte donc les kWh pour la facturation. Il calibre également le compteur pour une limite (en Watts) à la puissance appelable à un moment donné. C’est une limitation de débit. Cela peut vous empêcher de faire tourner à la fois le four électrique et le chauffe-eau, gros consommateurs d’électricité, mais ça ne vous interdit pas de les utiliser l’un après l’autre.
Une batterie, que ce soit de téléphone ou de voiture (électrique ou non) stocke de l’énergie et voit donc sa capacité exprimée en watts.heure. On peut aussi l’indiquer en ampères.heure. Dans ce cas, il faut multiplier cette dernière valeur par la tension nominale (volts) pour obtenir la capacité équivalente en watts.heure.
On voit passer parfois, au fil des articles, des “kilowatts par an” ou “mégawatts par heure”. Ces unités n’ont pas de sens physique directement utile. Elles indiquent en général une erreur.
Comment vérifier des consommations d’appareils électriques
Il est facile de vérifier soi-même la consommation des appareils électriques usuels avec un “consomètre”. Ainsi, vous n’aurez pas à prendre pour argent comptant ce qu’on affirme ici ou là. On en trouve pour moins de 15 €. Les modèles auto-alimentés (sans pile) sont en général préférables, évitent la corvée de piles et sont donc plus respectueux de l’environnement, mais peuvent perdre la mémoire en cas de coupure. Ces appareils permettent aussi bien de mesurer la consommation instantanée (la puissance, en W) que l’énergie utilisée sur une certaine durée (en kWh donc), pour les appareils qui ont une consommation fluctuante (par exemple, un frigo ne se déclenche que pour refaire un peu de froid quand c’est nécessaire).

Commençons par un objet courant, le point d’accès wifi.

Un point d’accès wifi de ce type, allumé, consomme environ 4 watts, tout le temps, indépendamment de son utilisation. Côté antenne wifi, la législation en France interdit une émission d’une puissance supérieure à 100 mW. Autrement dit, la consommation due à la transmission par l’antenne est au grossièrement (pour simplifier, car l’électronique interne sera également un peu plus sollicitée) 2,5 % de la consommation totale de la borne. L’interface ethernet (filaire) consomme un peu d’électricité elle aussi, mais celle-ci dépend de la longueur du câble plus que du volume de données transmis. Certaines bornes disposent ainsi d’un mode “vert” pour réduire la consommation électrique dans un environnement personnel, où les câbles mesurent quelques dizaines de mètres au maximum, plutôt que 100 mètres.
La différence de consommation entre une borne qui émet au maximum de sa capacité et une borne allumée sans aucun trafic sera donc au maximum de 2,5 %. En tout cas, il faut être conscient que diviser par 2 sa propre consommation de données ne divisera pas par 2 la consommation électrique associée, ni chez soi, ni ailleurs. Il est très facile avec un consomètre de le vérifier par soi-même pour la partie à domicile.
La box Internet
Les mêmes remarques s’appliquent à votre box d’accès Internet. Celle-ci va avoir, comme un point d’accès wifi, une ou plusieurs prises ethernet, et un accès au réseau de l’opérateur : aujourd’hui ADSL, VDSL ou fibre.
L’ARCEP a publié en 2019 un rapport sur l’impact carbone des accès à Internet. D’après un des acteur interrogés, “la fibre consomme en moyenne un peu plus de 0,5 Watt par ligne, soit trois fois moins que l’ADSL (1,8W) et quatre fois moins que le RTC [réseau téléphonique classique] (2,1W) sur le réseau d’accès”. Ces estimation de consommation ne varient pas du tout en fonction du volume transmis. En effet l’ADSL comme la fibre ont besoin d’émettre en permanence, que beaucoup ou peu de données soient transmises.
On voit aussi les progrès sensibles accomplis au fil des générations technologiques, puisque la consommation fixe décroît alors que le débit disponible augmente.
Par ailleurs, comme avec la borne wifi, la partie concernant la transmission longue distance présente une consommation marginale par rapport à celle de la box qui représente aux alentours de 10 à 30 watts suivant les générations. Les opérateurs travaillent d’ailleurs à la réduction de cette consommation, car elle devient un argument commercial.
Le téléphone mobile
Bon, la box Internet ou le point wifi ne consomment donc pas tant que ça. Qu’en est-il du téléphone mobile, présenté comme extrêmement gourmand ?
L’avantage du téléphone mobile est qu’il est alimenté par une batterie. Il est donc très facile d’estimer sa consommation maximale en fonctionnement : c’est celle d’une charge batterie complète, moins les pertes de celle-ci (faibles).
Une batterie de téléphone mobile d’aujourd’hui possède une capacité de 10 à 15 Wh. Elle peut donc fournir 10 à 15 W pendant une heure, ou la moitié pendant 2 h, etc.
L’éclairage d’écran d’un téléphone consomme à lui seul aux alentours de 2 W (facile à vérifier avec un consomètre assez sensible sur lequel on branche le chargeur). Cela représente le coût majeur lorsque vous visionnez une vidéo. La consommation est nettement plus élevée si vous préférez le faire sur un grand écran type téléviseur, et cela s’applique également à la télévision hertzienne classique.

Par comparaison, une ampoule LED consomme environ 8 watts pour remplacer à luminosité équivalente une ampoule à incandescence de 60 watts. Autrement dit, une charge de téléphone mobile n’a l’énergie pour éclairer une ampoule “basique” que pendant 1 à 2h. Il est évidemment important d’éteindre les pièces inoccupées, mais on en parle peu. Nous avons été convaincus que le téléphone mobile consommait bien plus, ce qui est faux.
Et le réseau mobile ?
Comme votre installation personnelle, la consommation du réseau de téléphonie mobile est essentiellement un coût fixe. L’équipement actif d’une antenne allumée va consommer quelques kilowatts ou dizaines de kilowatts, l’émission hertzienne proprement dite se contente de quelques dizaines de Watts, soit 100 fois moins. Autrement dit, la variable principale qui sous-tend la consommation électrique d’un réseau mobile est l’étendue de la couverture géographique, directement corrélée au nombre d’antennes.
Une étude finlandaise citée par le document Arcep a tenté d’estimer, pour la téléphonie mobile, la consommation électrique du réseau par rapport au volume de données, autrement dit le nombre de kWh par gigaoctet transféré (kWh/Go).
Pour effectuer de telles estimations d’impact environnemental, les méthodes dites d'”analyse du cycle de vie” (ACV) évaluent l’ensemble des coûts imputés par une activité. Ainsi, l’évaluation de l’empreinte de la téléphonie mobile intègre la fabrication des terminaux, la consommation personnelle (recharge quotidienne du téléphone), etc. Pour évaluer l’empreinte d’un opérateur mobile, on prend en compte la consommation des antennes, mais également la climatisation et chauffage des bureaux, etc. En divisant ce chiffre de consommation électrique totale par le volume échangé total, on peut obtenir une estimation de l’empreinte électrique du volume de données échangées.
Ce chiffre est intéressant pour évaluer l’empreinte totale des opérateurs, mais trompeur : il laisse entendre que la consommation électrique d’un opérateur mobile est totalement dépendante du volume échangé, ce qui est faux. Si du jour au lendemain tous les abonnés mobiles de France divisent leur consommation de données par 2, la consommation électrique des opérateurs ne va pas se réduire du même facteur : leurs antennes resteront allumées, leurs bureaux continueront à être climatisés et éclairés, etc.
L’étude finlandaise citée ci-dessus est intéressante à cet égard : on voit que la consommation électrique des opérateurs finlandais est restée à peu près stable pendant la décennie 2010, malgré une légère croissance tendancielle.
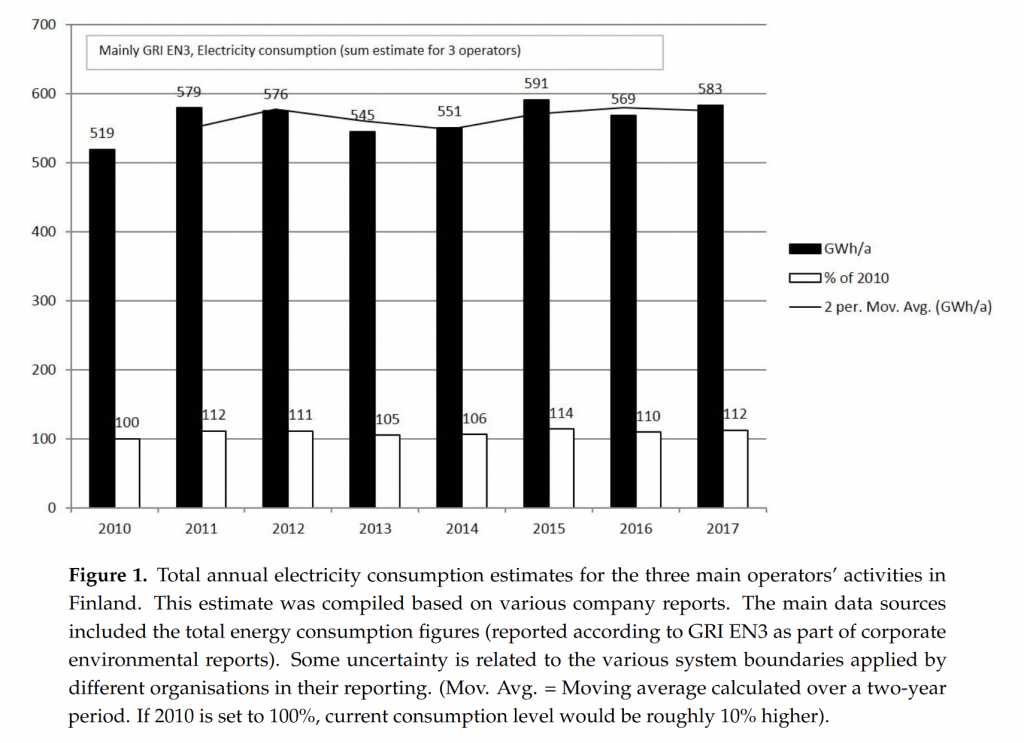
En revanche, les volumes échangés ont considérablement augmenté sur la même période :
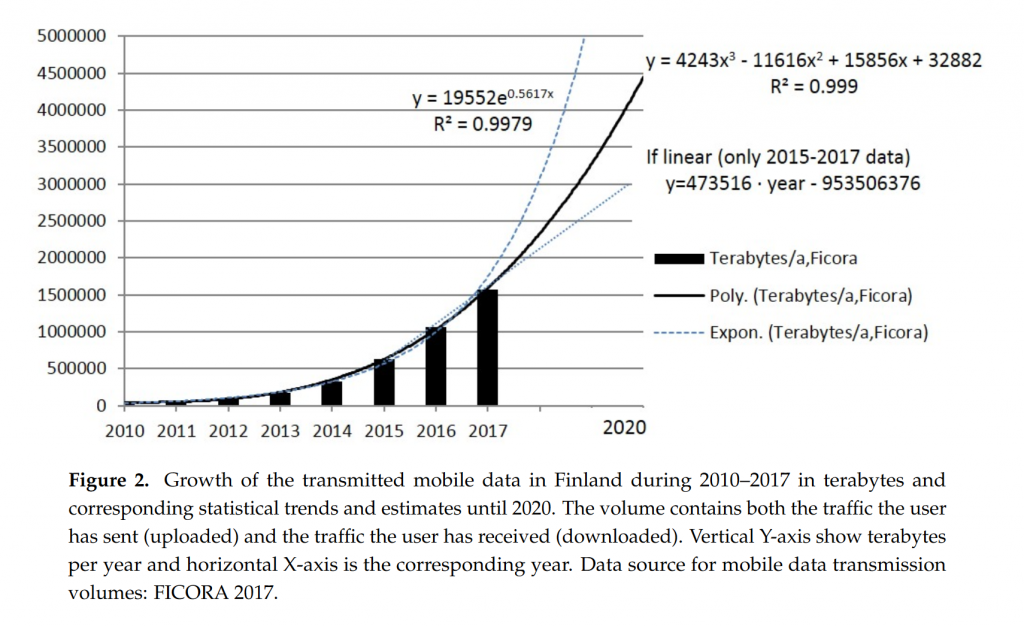
L’étude finlandaise utilise les deux graphes précédents pour en déduire un graphe d’efficacité énergétique en kWh/Go :
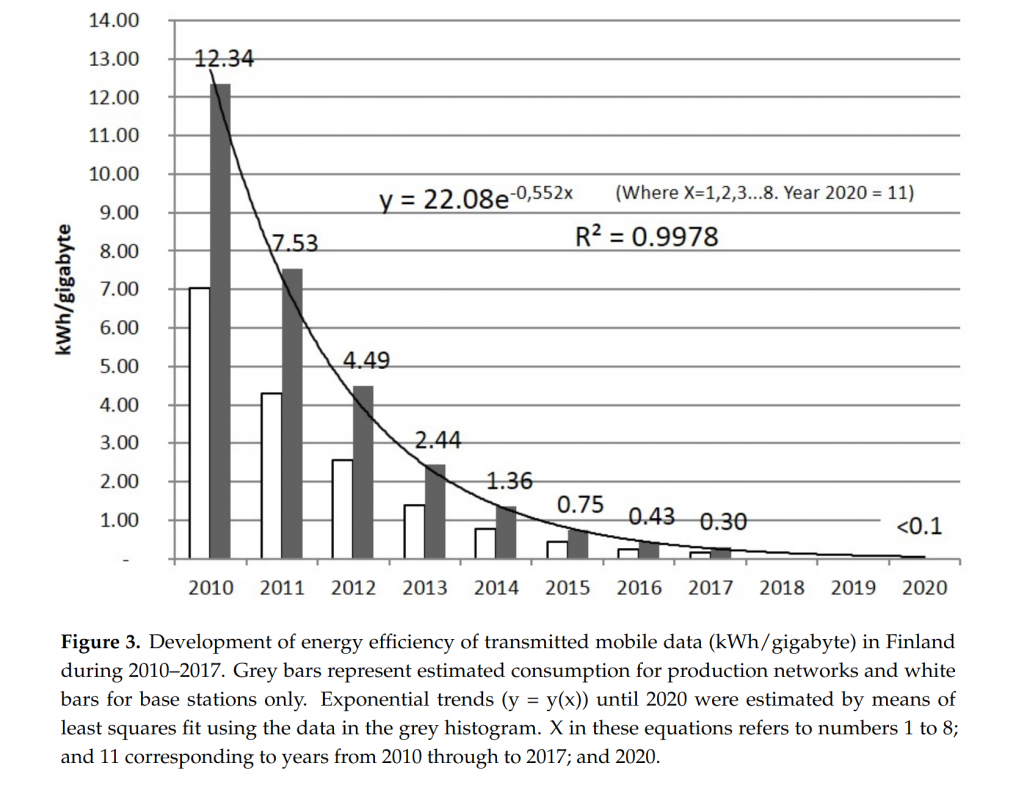
Si on ne prenait en compte que ce dernier graphe, ou même simplement une estimation ponctuelle en kWh/Go, on serait tenté de croire que doubler le volume de données va doubler la consommation énergétique associée, mais c’est totalement faux. Pour simplifier un peu, on ne ferait qu’introduire un nouveau point de données avec une efficacité énergétique multipliée par deux.
Bien sûr, les choses sont un peu plus complexes que ci-dessus. Augmenter la consommation en volume va provoquer l’installation de nouvelles antennes, de routeurs plus puissants, de liaisons fibre de plus grande capacité, peut-être de nouveaux liens terrestres pour développer le réseau. Inversement, comme on l’a vu ci-dessus, les générations technologiques permettent d’échanger des volumes de données toujours plus élevés avec une consommation électrique qui se réduit. Ces progrès, réels, ne sont que peu visibles dans les chiffres agrégés de kWh/Go, puisque ces derniers sont essentiellement constitués de coûts fixes sans rapport avec les technologies de transmission.
Le rapport ARCEP cité ci-dessus propose également une évaluation en termes de gaz à effet de serre (indicateur plus important que la consommation électrique), qui montre une baisse progressive de l’empreinte des opérateurs français.
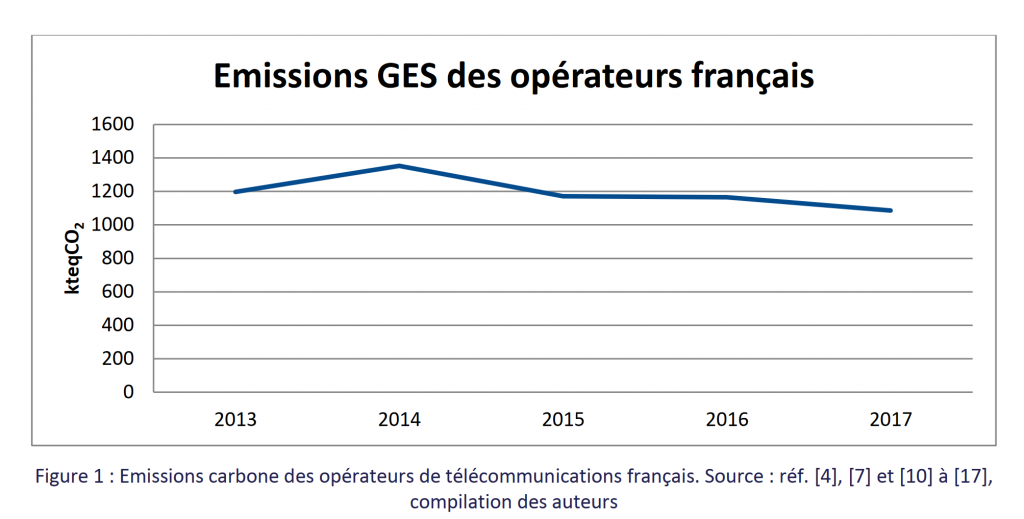
La section à laquelle ce graphique figure est d’ailleurs titrée “Une amélioration de l’efficacité énergétique qui compense, à ce stade, l’effet de l’explosion de trafic” pour résumer la situation.
Et les centres serveurs (datacenters) ?
Si tous les éléments cités ci-dessus ont une consommation faible, rien ne prouve que la consommation des datacenters n’est pas en train d’exploser pour répondre à la demande croissante ?
Une étude de l’agence internationale de l’énergie (IEA) montre, là encore, que la consommation électrique de ces centres n’explose pas, car les coûts principaux sont également des coûts fixes, et l’amélioration des équipements et de leur taux d’utilisation permet de traiter une quantité toujours croissante de services à consommation électrique égale.
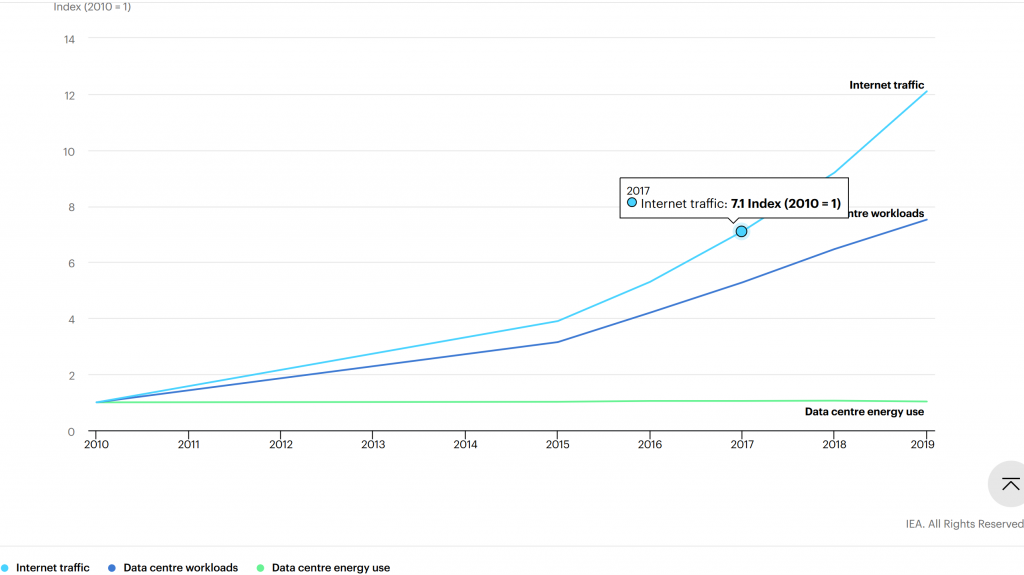
De 2010 à 2019, le volume réseau a ainsi été multiplié par 12 alors que la consommation électrique est restée remarquablement stable.
Faut-il vraiment réduire notre consommation de données ?
On voit d’abord qu’aucun des éléments de la chaîne, du serveur de données à notre installation personnelle, n’éprouve une sensibilité particulière aux volumes de données échangés. Il n’y a donc pas de raison écologique de se forcer à réduire notre consommation de celles-ci.
Il n’y a pas de raison non plus de forcer les opérateurs à le faire à notre place, en appelant à l’interdiction des forfaits illimités, ou à une obligation de facturation au volume. On notera d’ailleurs que ces envies de facturation proviennent historiquement des opérateurs eux-mêmes, et ont pu être liées à des initiatives pour remettre en cause la neutralité du réseau.
On peut légitimement arguer que l’électricité française est l’une des moins carbonées du monde (nos efforts en matière de consommation électrique ont donc beaucoup moins d’impact CO2 qu’ailleurs, à énergie économisée équivalente).
Mais puisque rien ne prouve qu’être sobre sur notre consommation de données aura le moindre impact significatif sur la consommation électrique, à quoi bon s’épuiser en efforts inutiles ?
Ce tweet résume d’ailleurs bien la question, pour montrer que le refus “par principe” de l’illimité n’a pas de sens :

En conclusion, la sobriété pour la sobriété, qu’elle soit volontaire ou forcée, n’est guère justifiable, et risque même de nous empêcher de profiter des externalités positives significatives, et reconnues, du numérique. Préférons donc la sobriété dûment justifiée.
Il est bien entendu utile d’éteindre sa box Internet, son accès wifi ou son ordinateur lorsqu’on ne s’en sert pas, comme on éteint la lumière ou le chauffage dans une pièce inoccupée. Il semble également établi, jusqu’à preuve du contraire — les données fiables sur la question sont rares en Europe –, que la fabrication des terminaux mobiles reste une activité consommatrice de ressources, il est donc utile d’utiliser les nôtres le plus longtemps possible pour mieux en amortir ce coût fixe.
Ce billet est resté succinct pour ne pas noyer le lecteur sous des tonnes de chiffres, mais n’hésitez pas à laisser un commentaire ici si vous avez des données pertinentes et sourcées qui pourront peut-être faire l’objet d’une deuxième couche 🙂