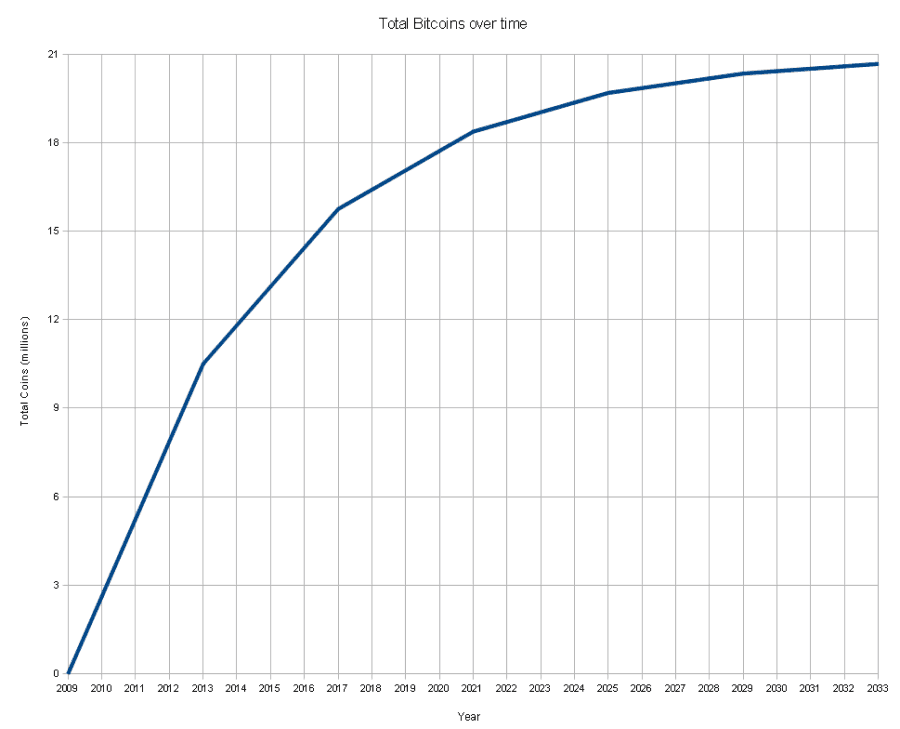
Ayant poursuivi mes réflexions après mon article précédent, je me suis intéressé au fonctionnement du minage de bitcoins.
Pour commencer, une petite démonstration de mathématiques
Supposons que vous ne soyez pas très bon en maths et que vous ne connaissiez que la multiplication, pas la division.
Par quels chiffres doit-on compléter les xxx dans 4025249123xxx pour que le résultat de sa multiplication par 7 se termine par 30 ?
Le plus simple est d’essayer les combinaisons une par une :
- 4025249123000 x 7 = 28176743861000
- 4025249123001 x 7 = 28176743861007
- 4025249123002 x 7 = 28176743861014
- 4025249123003 x 7 = 28176743861021
- 4025249123004 x 7 = 28176743861028
- 4025249123005 x 7 = 28176743861035
- …
En continuant ainsi on finit par tomber sur une bonne combinaison :
- 4025249123090 x 7 = 28176743861630
Mais ce n’est pas la seule, on aurait pu également trouver :
- 4025249123190 x 7 = 28176743862330
Une fois la solution trouvée, n’importe qui sachant calculer une multiplication peut la vérifier très rapidement.
Revenons à nos bitcoins…
Ce qui précède, c’est le principe général du “travail” Bitcoin, qui permet simultanément de rendre compliquées la création de monnaie et la validation des transactions, afin que n’importe qui ne fasse pas n’importe quoi, tout en rendant très facile leur vérification.
À la place de la multiplication par 7, on utilise une fonction de cryptographie appelée un hachage, ici SHA256, qui à partir d’un paquet de données binaires produit 256 bits de résultat (d’où son nom), d’une manière qu’on ne sait pas inverser. Ce genre de fonction est abondamment utilisé pour des signatures électroniques : le seul moyen pour trouver un paquet en entrée fournissant la sortie voulue, c’est de faire un grand nombre d’essais au hasard en appliquant la fonction (on dit force brute).
Ainsi le hachage SHA256 du paragraphe qui précède est 2756436ec1d5614b9e22840bf4f5bbbc580c897973d1e4607dc0a723f8d75073. En enlevant juste la première lettre, on obtient 6b8dc910fa3b2c8e3d40244869d5e1a5fe7753a1862eed5a306d2fceb6fe60fb.
À la place du nombre à compléter, on utilise une liste de transactions Bitcoin déjà signées par les clés des émetteurs, avec un emplacement à remplir appelé la nonce. (en fait le principe est similaire mais un petit peu plus compliqué, voir ce billet chez Turblog pour des détails techniques plus précis).
Au lieu de chercher un nombre se terminant par 30, on cherche un nombre inférieur à une certaine valeur, donc commençant par un certain nombre de zéros.
Et tous les ordinateurs du réseau Bitcoin cherchent simultanément des solutions à ce paquet, ce qui revient en gros à effectuer des tirages au sort vérifiables a posteriori.
En fait, plus précisément, chaque ordinateur cherche sa solution : car dans le paquet, il indique la transaction vers son compte, qui bénéficiera des Bitcoins qui rémunéreront son travail pour le paquet. Donc chacun trouve des valeurs SHA256 totalement différentes.
Le premier à trouver une solution a gagné. Il empoche le nombre de Bitcoins attribués au paquet (25 actuellement, 50 au début, et ce nombre va se réduire au fil du temps), et les commissions sur toutes les transactions du paquet.
La difficulté du problème (le nombre de chiffres prédéterminés dans la sortie) est ajustée afin qu’en moyenne, un nouveau paquet soit calculé toutes les 10 minutes.
Quel intérêt concret à être mineur ?
Évidemment, les ordinateurs rapides sont avantagés, et après l’exploitation des capacités de calcul rapide des cartes graphiques 3D, il existe maintenant des circuits électroniques spécialisés pour calculer beaucoup plus vite des hachages de paquets Bitcoin. Après les FPGA (circuits reprogrammables par le client), plus rapides moins gourmands en électricité (merci à Y. Rougy pour la précision) que les cartes graphiques, le Bitcoin est entré dans l’ère des ASIC (circuits intégrés classiques, fabriqués en usine pour cette application particulière, beaucoup plus rapides).
Ainsi, à la difficulté actuelle, il faudrait en moyenne 6882 années à mon ordinateur de bureau (14 millions de hachages par seconde) pour trouver un bloc et gagner 25 bitcoins. C’est ce que me dit ce calculateur de minage. Côté Litecoin, les algorithmes et difficultés sont différents, il ne me faudrait qu’environ 11 ans d’après https://www.litecoinpool.org/calc.
Pour comparaison, avec les circuits spécialisés les plus rapides du moment cités sur cette page de comparaison des performances matérielles, il faut environ 4 jours par bloc Bitcoin.
Plus il existe d’ordinateurs dans le réseau, et plus ils sont rapides, plus la difficulté est augmentée afin qu’il ne soit pas trop facile de créer de la monnaie et que le rythme moyen reste constant. Je ne sais pas si la réciproque est vraie (mais je pense que oui, le protocole semblant bien pensé) : on peut imaginer que la force de calcul se réduise soudainement, soit par disparition d’une équipe de mineurs, soit par panne, etc.
Il existe en tout cas une véritable course aux capacités de calcul : l’ajout de capacité avantage celui qui la détient, mais pousse la difficulté générale à la hausse, toutes choses égales par ailleurs en termes de services effectifs rendus.
La rentabilité du minage de bitcoins dépend du cours de celui-ci, de la difficulté des calculs et des coûts d’investissement et de fonctionnement (électricité et climatisation, notamment). Si l’activité est très rentable, elle attirera beaucoup de mineurs, ce qui en réduira mécaniquement la rentabilité de deux manières, augmentation de la difficulté et répartition des gains sur un plus grand nombre de mineurs.
Groupes de minage ou minage solo
Il existe un écueil au minage : les temps élevés pour découverte d’un bloc. On gagne beaucoup, mais très rarement, et rien du tout la plupart du temps. C’est pour cela que des groupes se constituent, visant à multiplier les chances de récupérer des blocs, et lissant les gains en les répartissant au sein du groupe.
Cette page sur le wiki Bitcoin présente plus en détail l’activité des groupes de mineurs, et ce comparatif décrit les groupes, notamment les différentes façons de répartir les gains.
La gestion de groupes introduit un autre problème intéressant : le taux de découverte de bloc étant très faible, comment s’assurer que les mineurs qui ne trouvent pas cherchent effectivement et ne sont pas des parasites qui ne viennent qu’empocher leur part des gains ? Des méthodes ont été inventées pour donner des preuves de travail.
Solo = Loto ?
Pour rire, j’ai voulu comparer les espérance de gain du minage en solo à celles, assez similaires, d’un gain de 5 numéros au Loto pour quelqu’un qui jouerait une fois par semaine.
Sauf erreur de ma part, donc :
- gain (calculé sur un cours de 600€ par bitcoin soit 25 bitcoins = 15 000€) environ 6 fois plus faible
- chances de gain 3 fois plus élevée (temps moyen par bloc : 6882 ans au lieu de 20 000 ans environ)
- dépense équivalente : en supposant une consommation de l’ordinateur d’environ 100 W donc 16,8 KWh chaque semaine, soit 2,23€, contre 2€ la grille de Loto.
- et je n’ai pas inclus le coût d’acquisition et d’amortissement de l’ordinateur.
- il faut ajouter, aux gains du Bitcoin, les commissions de transaction, qui représentent relativement peu actuellement (environ 0,2 à 0,4 bitcoin par bloc en général ; tout cela est visible sur blockchain.info)
Je précise que cette évaluation à la louche ne tient pas compte d’autres facteurs potentiels, notamment les refus peut-être plus probables d’un bloc si votre ordinateur est vraiment très lent, ou des délais de transmission, qui réduisent peut-être notablement les chances effectives de gains. En effet je n’ai jamais trouvé un bloc Bitcoin de ma vie, ce qui n’est pas étonnant quand on sait que je n’ai pas beaucoup tenté ma chance.
Si on intègre les rapports complets du Loto (tous les gains, pour toutes les combinaisons de chiffres), c’est moins glorieux pour le Bitcoin. En effet, au Loto on peut espérer récolter environ 1€ par semaine, soit 358 000 euros en 6882 années, ce qui représente 24 fois les gains en Bitcoin au cours actuel.
Mais, quand on se rappelle que tout cela chatouille gentiment les pieds des États, des banques centrales et des banques de détail, ce que ne fait pas du tout le Loto, on conviendra que cette satisfaction immatérielle a elle aussi une certaine valeur.
Commentaires et corrections bienvenus, bien entendu.